| System Structure

다섯째날인 오늘은 Hadoop을 설치해보겠습니다.
Hadoop 구성에 대해서 설명드리자면,
우선 NamodeNode(master) 1대 Datanode3(slave)대 그리고 마지막으로 client로 되어있습니다.
NameNode는 NameNode 역할을 하면서 datanode1 역할도 합니다.
(분리했으면 좋겠지만 서버가 늘어나면 aws 비용 문제로 분리하지 않았습니다. 분리하고 싶으신분들은 namenode와 datanode를 분리해도 됩니다.)
SecondaryNameNode는 SecondaryNameNode 역할도 하면서 datanode2 역할도 합니다.
또한 Resource Manager입니다. namenode에 Resource Manager로 할 수도있지만, namenode에게 많은 부하를 주는 것을 방지하기 위해서 역할을 나누었습니다.
namenode에 Resource Manager를 주셔도 됩니다.
datanode3은 datanode3입니다.
마지막으로 client 서버로 구성되어있습니다.
목차
1. AWS 로그인 및 EC2(Putty) 접속
2. Hadoop 설치
2.1 Hadoop 설치
2.2 Hadoop 압축해제
2.3 Hadoop 환경설정
내용
1. AWS 로그인 및 EC2(Putty) 접속
[root@ip-172-31-40-48 ~]# su - hadoop
2. Hadoop 설치
2.1 Hadoop 설치
[hadoop@ip-172-31-40-48 ~]$ sudo wget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz

(참고) 만약 위의 명령어가 오류 난다면 아래를 참고해주세요.
Http request sent, awiting response... 404 Not Found.

hadoop을 다운받는 방법은 2가지가 있습니다.
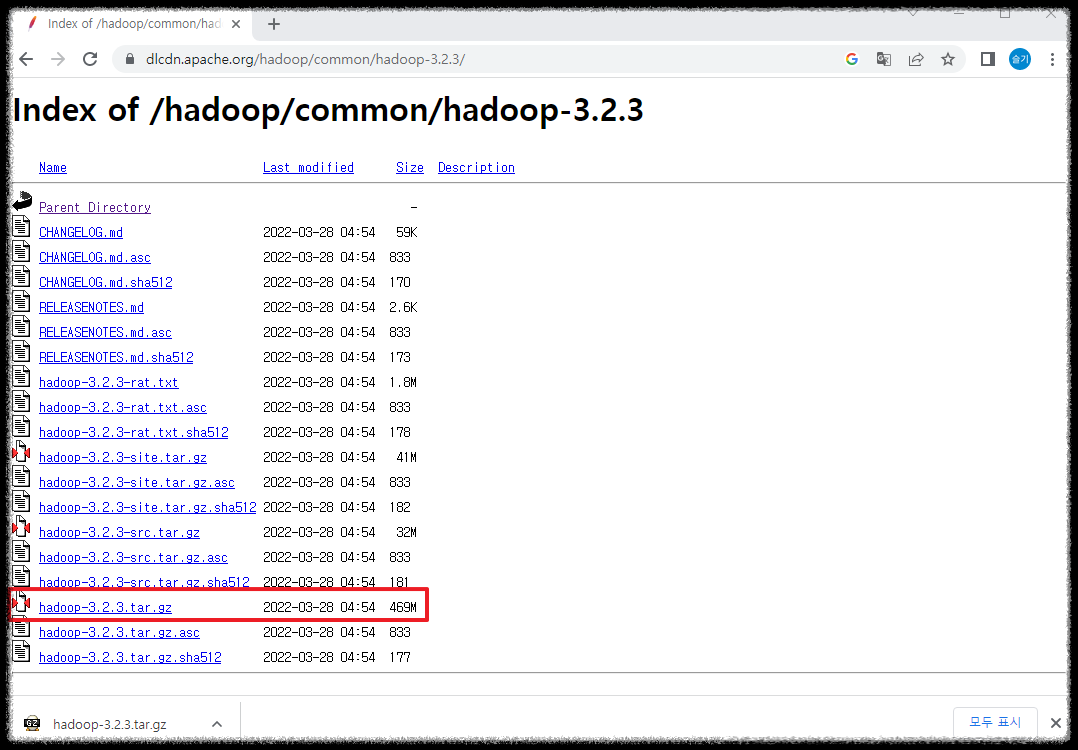
첫번째. 홈페이지 직접 접속
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/
Index of /hadoop/common/hadoop-3.2.3
dlcdn.apache.org
두번째 wget으로 설치 하지만 wget 명령어가 에러가 난다면 아래처럼 해주세요.
1) wget가 설치되어있는지 확인
-> yum install wget -y
2) 사이트 주소와 다운받을 자원이 올바른지 확인

2.2 Hadoop 압축해제
[hadoop@ip-172-31-40-48 ~]$ tar -zxvf hadoop-3.2.3.tar.gz
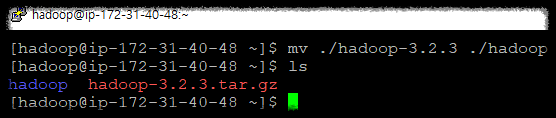
2.2.1 폴더 이름 변경
hadoop-3.2.3 이름을 hadoop으로 변경합니다.
[hadoop@ip-172-31-40-48 ~]$ mv ./hadoop-3.2.3 ./hadoop
혹시 root 계정으로 설치했거나 Hadoop 설치 위치를 다르게 하신분들은 아래를 참고해주세요
참고로 현재 설치 위치는 "/home/hadoop" 입니다.
폴더 옮기기
hadoop 폴더 /home/hadoop/ 밑으로 옮기기
[hadoop@ip-172-31-40-48 ~]$ mv hadoop/ /home/hadoop/
[root@client local]# ls /home/hadoop/hadoop/

소유자 변경
root 계정으로 설치시 hadoop 계정이나 혹은 hadoop을 설치한 계정이 hadoop을 참조할 수 있게 소유자를 변경해야 합니다.
[root@client ~]# cd /home/hadoop/
[root@client hadoop]# chown -R hadoop:hadoop .
[root@client hadoop]# ls -al
total 20
drwx------. 4 hadoop hadoop 125 Nov 22 03:27 .
drwxr-xr-x. 4 root root 36 Nov 18 05:35 ..
-rw-------. 1 hadoop hadoop 341 Nov 22 03:27 .bash_history
-rw-r--r--. 1 hadoop hadoop 18 Nov 5 2021 .bash_logout
-rw-r--r--. 1 hadoop hadoop 141 Nov 5 2021 .bash_profile
-rw-r--r--. 1 hadoop hadoop 584 Nov 18 07:45 .bashrc
drwxr-xr-x. 9 hadoop hadoop 149 Mar 20 2022 hadoop
drwxr-xr-x. 2 hadoop hadoop 24 Nov 18 07:41 .vim
-rw-------. 1 hadoop hadoop 3729 Nov 22 03:27 .viminfo
2.3 Hadoop 환경설정
[hadoop@ip-172-31-40-48 ~]$ vi ~/.bashrc
"Mapreduce" 애플리케이션의 경우 기본값 외에 HADOOP_MAPRED_HOME을 추가해야 합니다.
속성 값은 HADOOP_COMMON_HOME, HADOOP_HDFS_HOME, HADOOP_CONF_DIR, HADOOP_YARN_HOME, HADOOP_HOME, PATH, HADOOP_MAPRED_HOME 등이 있습니다.
맵리듀스(Mapreduce)란 대용량 데이터를 처리를 위한 분산 프로그래밍 모델로 Key와 Value 형태로 데이터를 묶는것은 Map, Map화 한 작업 중 중복 데이터를 제거하는 과정은 Reduce라고 합니다.
########################## HADOOP ##########################################
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
#############################################################################
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
혹시 HAOOP 실행만 보실 분들은 아래 두부분만 넣어도 HADOOP은 잘 실행됩니다.
export HADOOP_HOME=/home/hadoop/hadoop
$HADOOP_HOME/sbin:$HADOOP_HOME/bin
[hadoop@ip-172-31-40-48 ~]$ source ~/.bashrc
[hadoop@ip-172-31-40-48 ~]$ echo $HADOOP_HOME

'💻 개발과 자동화' 카테고리의 다른 글
| [AWS-EC2 Hadoop|Hive|Spark] 인스턴스 복사(AMI 생성) + 이미지/인스턴스 삭제 (0) | 2022.12.08 |
|---|---|
| [AWS-EC2 Hadoop|Hive|Spark] Hadoop 3.2 설정파일 설정 (0) | 2022.12.07 |
| [AWS-EC2 Hadoop|Hive|Spark] 계정생성 Java8설치 + selinux해제 (0) | 2022.12.05 |
| [AWS-EC2 Hadoop|Hive|Spark] 인스턴스 putty 접속 + root 접속 + puttygen .ppk 생성 + (0) | 2022.12.04 |
| [AWS-EC2 Hadoop|Hive|Spark]인스턴스 생성, 시작과 종료 (0) | 2022.12.03 |




댓글