- 데이터 전처리란?
데이터를 분석 및 처리에 앞서 알맞은 형태로 만드는 것이다.
- 데이터 전처리 사용
Data 분석, Data 마이닝, 머신/답 러닝 프로젝트에 적용됨
- 데이터 분석 단계
| 1. 문제 정의 2. 데이터 수집 3. 데이터 전처리 4. 데이터 모델링 5. 시각화 및 탐색 |
여기서는 데이터 전처리까지만 하도록 한다.
1. 문제 정의
1. 2016에서 승차가 가장 많은 역 Top 5
2. 서울역에서 가장 이동인구가 많은 시간대(승차,하차)
2. 데이터 수집
혹은 아래와 같은 사이트에서 공공데이터 수집 가능합니다.
| 사이트명 | 사이트 주소 |
| 공공데이터 포털 | https://www.data.go.kr/ |
| KT 통신 빅데이터 플랫폼 | https://bdp.kt.co.kr/ |
| 서울 열린 데이터 광장 | https://data.seoul.go.kr/ |
| 국가 통계 포털 | https://kosis.kr/ |
| 서울특별시 빅데이터 캠퍼스 | https://bigdata.seoul.go.kr/ |
| 통계청 | https://kostat.go.kr/ |
| 한국소비자원 | http://www.price.go.kr/ |
3. 데이터 전처리
데이터 전처리에는 아래와 같은 처리들을 합니다.
- 여러 개의 데이터 파일을 하나로 합치기
- 데이터 실수화: 문자열, 범주형 데이터 등의 데이터를 컴퓨터가 이해할 수 있는 실수형으로 변환
- 불완전 데이터(결측치) 제거: NaN, NA, NULL 값 등을 제거
- 데이터 노이즈 제거
-> 이상하고 모순된 값
참고 : https://skyil.tistory.com/100
주요 데이터 전처리 기법에 대해서는 나중에 자세히 다뤄보도록 하겠습니다.
본격적으로 Data전처리를 시작하도록 하겠습니다.
Jupyter Notebook에 Subway.zip 파일을 올려주세요.2016년 1월부터 12월 자료가 있습니다.

subway 폴더에 있는 파일 list를 확인해보겠습니다.
import os
os.listdir('./subway')
읽어온 파일들을 df_all_subways에 하나의 파일로 합치고 혹시 데이터가 망가질 것을 염두해서 copy 명령어를 이용하여 백업하겠습니다.
# 파일 한번에 읽기
folders= os.listdir('./subway')
cd ./subway
df_all_subways = []
for file in folders:
df_all_subways.append(pd.read_csv(file, encoding='euc-kr'))
df_all_subways
# 원본 데이터 백업하기 -> copy
df_all_subway_back=df_all_subways.copy()
df_all_subway_back
데이터 전처리를 하기 위하여 컬럼명을 확인하고 통일하도록 하겠습니다.
# 컬럼명 확인 및 통일
for idx, df in enumerate(df_all_subways):
print(idx, df.columns)
통일할 최종 컬럼명은 아래와 같습니다. -> INDEX5와 동일
'역명', '날짜', '구분', '05~06', '06~07', '07~08', '08~09', '09~10', '10~11',
'11~12', '12~13', '13~14', '14~15', '15~16', '16~17', '17~18', '18~19',
'19~20', '20~21', '21~22', '22~23', '23~24', '00~01', '01~02'
동일한 컬럼명끼리 묶어서 처리하겠습니다.
1~5월까지 컬럼명이 동일하기 때문에 df1에 저장, 6~11월은 df2에 저장
12월은 시간 뒤에 "시"가 붙어있기 때문에 df3으로 혼자 저장하겠습니다.
df1 = pd.concat([x for x in df_all_subways[:5]])
df2 = pd.concat([x for x in total[5:]])
df3=df_all_subways[11]
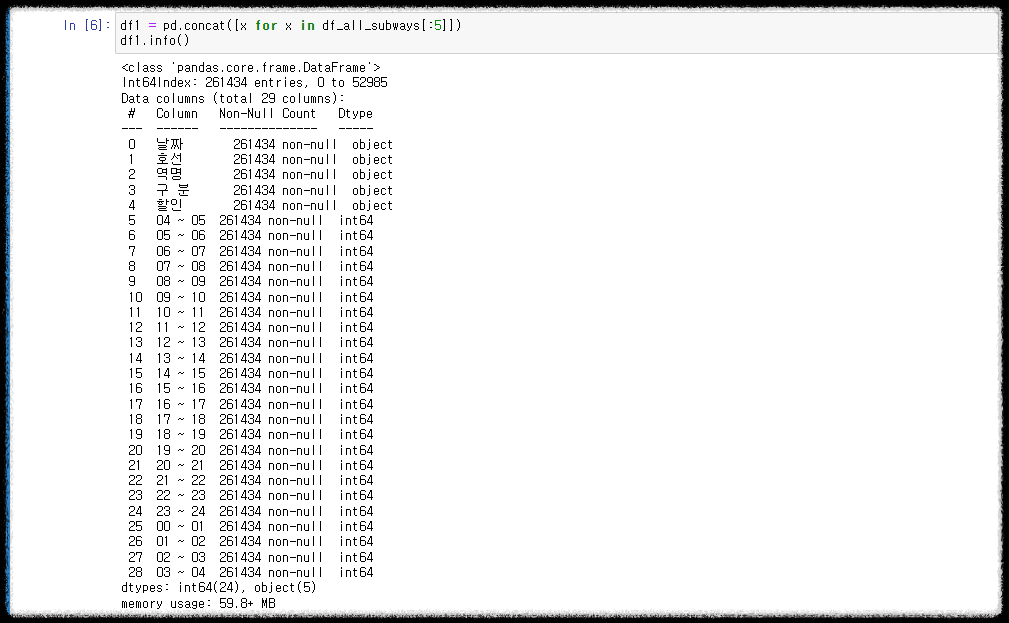
- 컬럼명의 띄어쓰기를 없앤다.
df1.columns = [x.replace(" ", "") for x in df1.columns]
- 컬럼을 없앤다. '호선', '할인', '04~05', '02~03', '03~04'
df1.drop(['호선', '할인', '04~05', '02~03', '03~04'], axis=1, inplace=True)df2는 수정할 것이고 없고, 12월달이 있는 데이터는 df3은 시간 뒤에 있는 "시"를 없애줍니다.
- "시"를 없앤다.
df3.columns =[x.replace("시", "") for x in df3.columns]
컬럼명을 정리한 df1, df2 그리고 df3을 합치겠습니다.
# 컬럼 합치기
subway_all = pd.concat([df1, df2, df3])
subway_all
누락된 데이터가 있는지 확인합니다.
뒤에 0이 아닌 숫자가 있으면 그만큼 누락되었다는 뜻이고 데이터 컬럼명 정리를 다시해야합니다.
# 누락된 컬럼 확인하기
subway_all.isnull().sum()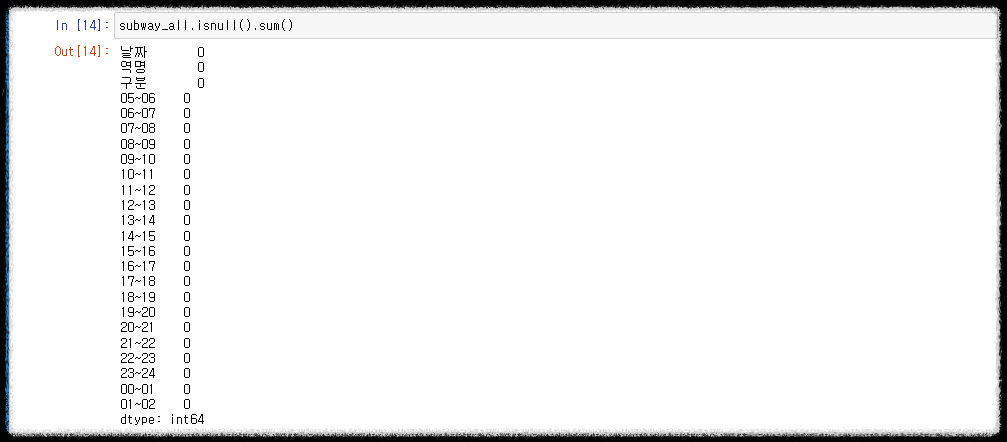
지금까지는 컬럼명 통일했고 이제는 데이터 확인 및 전처리를 하겠습니다.
# 데이터 확인 및 전처리
- 역 뒤에 오는 (숫자)를 없애고 역으로 통일
ex) 서울역(150) -> 서울역
남태령(434) -> 남태령
정규식을 이용하여 괄호와 숫자를 제거한 한국어 텍스트만 남겼습니다. 또한 람다함수를 사용했습니다.
# [참고]
정규식 연습 사이트 : https://regex101.com
import re
p = re.compile("([가-힣]+)")
subway_all['역명'] = subway_all.역명.apply(lambda x : p.findall(x)[0])
subway_all.역명.apply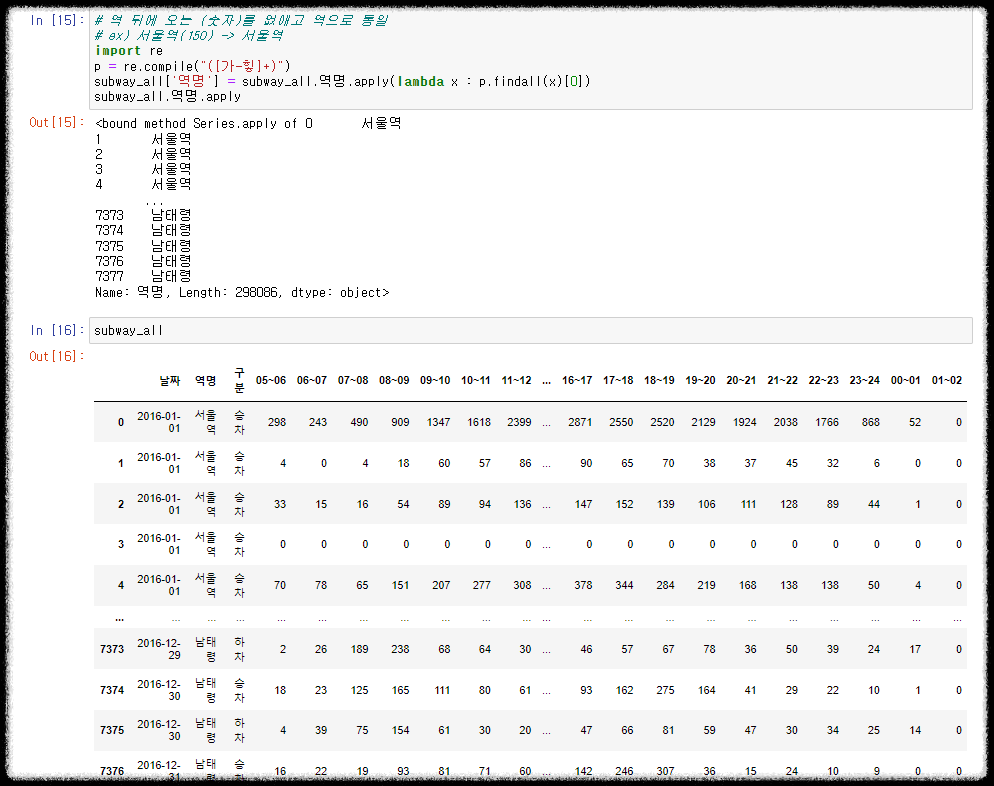
1. 문제 정의에 대한 답변
1. 2016에서 승차가 가장 많은 역 Top 5 -> 강남역
# numeric_only 최빈값
subway_all['합계'] = subway_all.sum(numeric_only=True, axis=1)
# ascending 오름차순
subway_all.query(" 구분 == '승차' ").groupby(['합계','역명', '구분','날짜']).sum().sort_values(by=['합계'], ascending=False).head(5)강남역이 결과라는 것을 알 수 있습니다.

2. 서울역에서 가장 이동인구가 많은 시간대(승차,하차) -> 승차 18~19시 / 하차 08~09시
# 2. 서울역에서 가장 이동인구가 많은 시간대(승차,하차)
# 승차
subway_all.query("역명 == '서울역' and 구분 =='승차'").sum(numeric_only=True).sort_values(ascending=False).head(2)
# 하차
subway_all.query("역명 == '서울역' and 구분 =='하차'").sum(numeric_only=True).sort_values(ascending=False).head(2)
아직 데이터 전처리가 익숙치 않아 내맘 같지 않네요... 시간이 되면 더욱더 연습해봐서 익숙해지도록 하겠습니다 :)
'💻 개발과 자동화' 카테고리의 다른 글
| [AWS-EC2 Hadoop|Hive|Spark]AWS 회원가입, 계정 삭제, 비밀번호 변경 (2) | 2022.11.16 |
|---|---|
| [Git] Git & GitHub 설치 및 환경 설정하기 (0) | 2022.11.13 |
| [Web Scraping] 여러개 이미지 저장하기 (8) | 2022.10.19 |
| [Web Scraping] os 모듈과 chunk로 하나의 이미지 저장하기 (4) | 2022.10.18 |
| [Web Scraping] 네이버웹툰 - 인기 웹툰 및 제목, 링크, 평점 가져오기 (8) | 2022.10.10 |




댓글