최근에 웹 스크랩핑을 하고 있는데 정말 어렵더라구요!
저번에는 웹 스크랩핑을 이용하여 하나의 이미지를 다운 받았는데 이번에는 여러개의 이미지를 다운받으려고 합니다.
하나의 이미지 다운받는 방법이 궁금하시면 아래 사이트 참고해주세요.
https://seul96.tistory.com/m/378
[Web Scraping] os 모듈과 chunk로 하나의 이미지 저장하기
최근에 웹 스크랩핑을 하고 있는데 정말 어렵더라구요! 오늘은 웹 스크랩핑을 이용하여 먼저 하나의 이미지를 받은 후에 여러개의 이미지를 받으려고 합니다. 책은 데이터 분석을 위한 파이썬
seul96.tistory.com
데이터 분석을 위한 파이썬 철저 입문책을 참고했습니다 :)
# 웹 스크랩핑을 이용하여 여러 이미지 내려받기
사이트는 무료 이미지를 제공하는 https://www.reshot.com에서 animals를 검색해보겠습니다.
https://www.reshot.com/free-svg-icons/animals/
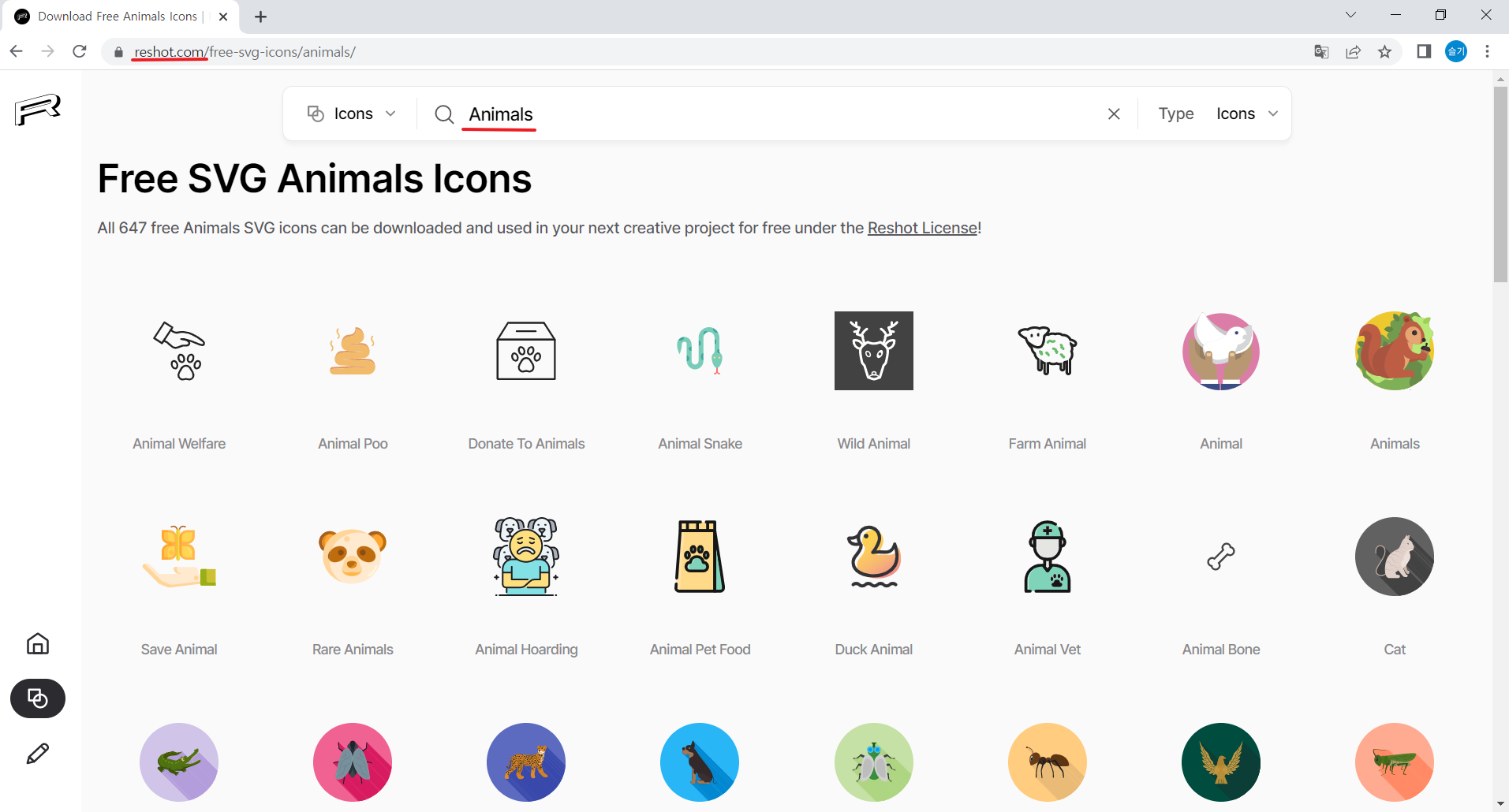
먼저 requests와 BeautifulSoup을 import 합니다. 다음은 url을 설정해주고 진짜 내가 들어가는 것처럼 headers도 선언하여 text를 가져옵니다.
import requests as req
from bs4 import BeautifulSoup as bea
url = 'https://www.reshot.com/free-svg-icons/animals/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
html = req.get(url, headers).text
soup = bea(html, "lxml")
print(soup.prettify)
결과 :
<bound method Tag.prettify of <!DOCTYPE html>
<html lang="en">
<head>
<title>Download Free Animals Icons | Reshot</title>
<meta content="width=device-width" name="viewport"/>
<meta charset="utf-8"/>
<link href="https://www.reshot.com" rel="preconnect"/>
<link href="https://res.cloudinary.com" rel="preconnect"/>
<link href="https://envato-shoebox-0.imgix.net" rel="preconnect"/>
<link href="https://cdn.rollbar.com" rel="preconnect"/>
<link href="https://www.googletagmanager.com" rel="preconnect"/>
<link href="https://www.google-analytics.com" rel="preconnect"/>
<link as="image" href="https://www.reshot.com/build/reshot-logo--mark-f8dfafbc1cc8fbf4dfa0e2f210265735aefa6e32f883b5a1fe27fd94f84719b3.svg" rel="preload"/>
... 이하 생략 ...그림의 url 주소들을 추출하기 위하여 아래와 같이 합니다.
개발자 모드(F12) -> 마우스 커서(select an element in the page to inspect it) -> 아무 그림
그러면 a 태그 안에 있는 div 태그에 url이 있는 것을 확인 할 수 있습니다.

좀 더 확대해서 보면 아래와 같습니다. 여기서 이미지 url 주소인 https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg만 가져오고 싶은겁니다.
<a class="icons-card__link" aria-label="Link to item page" rel="nofollow" href="/free-svg-icons/item/animal-welfare-M9LE6FPZJS/">
<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg)"></div>
<span class="icons-card__title">Animal Welfare</span>
</a>
BeautifulSoup의 select를 이용하여 a 태그 안에 있는 div 태그 부분을 확인합니다.
divs = soup.select('a > div')
divs
결과 :
[<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg)"></div>,
<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/HGCXQSFMU2/animal-poo-HGCXQSFMU2.svg)"></div>,
<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/BGD28R7WUF/donate-to-animals-BGD28R7WUF.svg)"></div>,
<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/28XD6SR4BJ/animal-snake-28XD6SR4BJ.svg)"></div>,
... 이하 생략 ...
이렇게 하면 이미지들의 url이 들어있는 div 태그만 추출된 것을 확인할 수 있습니다.
하지만 문제점으로는 url 부분만 출력하고 싶은데 속성값에 바로 들어있는 것이 아니라서 정규식을 이용하여 괄호() 안에 있는 url부분만 추출해보도록 하겠습니다.
정규식은 보통 문자열의 검색과 치환을 위한 용도로 많이 사용됩니다.
정규식을 사용하기 위하여 re를 import 합니다.
그리고 ()안에 있는 내용만 추출하는 정규식은 "(?<=\()[^)]*(?=\))" 입니다.
정규식에 대해서 좀더 궁금한사람은 아래 설명을 읽어주세요
# 정규식
정규식에 대해서 좀 더 이해를 할 수 있게 예시를 들어보겠습니다.
1. ()안의 url만 추출하고 싶은 String을 하나 선언합니다. -> test_r
2. ()안의 내용만 추출하는 정규식을 선언해줍니다. -> a
3. findall을 이용하여 () 안의 url 부분만 추출합니다.
import re
test_r='<div class="icons-card__image" style="--image: url(https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg)"></div>'
a = re.compile("(?<=\()[^)]*(?=\))")
a.findall(test_r)
결과 : ['https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg']
import re
# 정규식 사용하여 ()안 url 부분만 추출
a = re.compile("(?<=\()[^)]*(?=\))")여러개의 이미지의 주소를 추출하기 위하여 for문을 사용합니다.
for x in divs:
print(a.findall(x['style'])[0])
결과 :
https://www.reshot.com/preview-assets/icons/M9LE6FPZJS/animal-welfare-M9LE6FPZJS.svg
https://www.reshot.com/preview-assets/icons/HGCXQSFMU2/animal-poo-HGCXQSFMU2.svg
https://www.reshot.com/preview-assets/icons/BGD28R7WUF/donate-to-animals-BGD28R7WUF.svg아래와 같이 ()안의 url만 추출된 것을 확인 할 수 있습니다.

다음으로는 os 모듈을 이용하여 만들고 싶은 폴더 여부를 확인하여 없을 때 생성해 보도록 하겠습니다.
# 폴더 생성 및 지정
import os
figure_folder = 'C:/Users/Playdata/folder_img'
if not os.path.exists(figure_folder):
os.makedirs(figure_folder)결과 :

다음으로는 각각의 이미지 주소를 추출하고 리스트 image_urls에 저장하도록 하겠습니다.
# 이미지 주소 추출
image_urls = []
for x in divs:
image_urls.append(a.findall(x['style'])[0])다음으로는 폴더를 지정해서 이미지를 내려받는 download_image 함수를 선언해보겠습니다.
# 폴더를 지정해 이미지 주소에서 이미지 내려받기
def download_image(img_folder, img_url):
if(img_url != None):
html_image = req.get(img_url)
# os.path.basename(URL)는 웹사이트나 폴더가 포함된 파일명에서 파일명만 분리
imageFile = open(os.path.join(img_folder, os.path.basename(img_url)), 'wb')
chunk_size = 1000000 # 이미지 데이터를 1000000 바이트씩 나눠서 저장
for chunk in html_image.iter_content(chunk_size):
imageFile.write(chunk)
imageFile.close()
print("이미지 파일명 : '{0}'. 다운로드 완료".format(os.path.basename(img_url)))
else:
print("다운받을 이미지가 없습니다.")-> 사실 데이터 분석을 위한 파이썬 철저입문책의 내용을 가져왔으나 책의 웹 스크랩핑 방법으로는 현재는 이미지가 추출되지 않아, 테스트를 하는데 어려움을 많이 겪었습니다. 또한 위의 함수 부분은 100% 이해가 되지 않아 이해가 되는날에 다시 서술해보도록 하겠습니다.
무튼 downlad_image 함수를 이용하여 폴더와 파일명을 읽어보고 다운 받을 chunk를 선언하는 코드입니다.
다음으로는 진짜로 여러개의 이미지를 다운받아보도록 하겠습니다.
num_of_download_image = 7 # 내려받을 이미지 개수 지정
# num_of_download_image = len(pixabay_image_urls)
for k in range(num_of_download_image):
download_image(figure_folder,image_urls[k])
print("선택한 모든 이미지 다운이 완료되었습니다.")
결과 :
이미지 파일명 : 'animal-welfare-M9LE6FPZJS.svg'. 다운로드 완료
이미지 파일명 : 'animal-poo-HGCXQSFMU2.svg'. 다운로드 완료
이미지 파일명 : 'donate-to-animals-BGD28R7WUF.svg'. 다운로드 완료
이미지 파일명 : 'animal-snake-28XD6SR4BJ.svg'. 다운로드 완료
이미지 파일명 : 'wild-animal-LA4MVFCEZQ.svg'. 다운로드 완료
이미지 파일명 : 'farm-animal-WDBEX9PUYL.svg'. 다운로드 완료
이미지 파일명 : 'animal-ELD34VBWFT.svg'. 다운로드 완료
선택한 모든 이미지 다운이 완료되었습니다.
folder_img 폴더를 확인하시면 아래와 같이 7개의 이미지가 설치된것을 확인할 수 있습니다.

다음에는 pandas를 이용하여 데이터 전처리와 download_image 함수를 좀 더 이해보도록 하겠습니다.
++ 추가
기존의 download_image를 아래와 같이 수정 및 혼자서 이해해보았습니다.
def download_image(img_folder, img_url):
html_image = requests.get(img_url)
imageFile = open(os.path.join(img_folder, os.path.basename(img_url)), 'wb')
chunk_size = 1000000 # 이미지 데이터를 1000000 바이트씩 나눠서 저장
for chunk in html_image.iter_content(chunk_size):
imageFile.write(chunk)
imageFile.close()
print("이미지 파일명: '{0}'. 내려받기 완료!".format(os.path.basename(img_url)))download_image 매개변수로 img_folder과 img_url 입니다.
img_folder는 'C:/Users/Playdata/folder_img'로 파일을 다운받을 폴더 입니다.
img_url은 하나의 이미지 url 주소입니다.
나눠서 다운받기 위하여 iter_content(chunk_size)를 사용 했으며, iter_content(chunk_size)를 사용하기 위해서는 request 응답을 받아온 객체여야 합니다. 즉 requests.get(img_url)로 받아옵니다.
다음으로는 각각의 파일을 읽고 닫으면서 파일이 다운 완료 됩니다.
아직까지는 웹 스크랩핑이 많이 부족하지만 열심히 반복하다 보면 실력이 늘어날것이라고 믿습니다 :)
'💻 개발과 자동화' 카테고리의 다른 글
| [Git] Git & GitHub 설치 및 환경 설정하기 (0) | 2022.11.13 |
|---|---|
| [Python] Pandas를 이용하여 DATA전처리 (지하철DATA) (0) | 2022.11.03 |
| [Web Scraping] os 모듈과 chunk로 하나의 이미지 저장하기 (4) | 2022.10.18 |
| [Web Scraping] 네이버웹툰 - 인기 웹툰 및 제목, 링크, 평점 가져오기 (8) | 2022.10.10 |
| [Web Scraping] Naver Webtoon - 요일별 전체 웹툰 제목 가져오기 (0) | 2022.10.09 |




댓글