Web Scraping
국비지원에서 웹 스크랩핑을 배웠는데, 익숙해지지 않아 연습을 해보려고 한다.
데이터 분석을 위한 파이썬 철저 입문책과 국비지원수업 내용을 참고했다.
오늘 구현할 내용은 아래와 같다.
# Workshop
네이버 웹툰
https://comic.naver.com/webtoon/weekday
1. 요일별 전체 웹툰 제목 모두 가져오기
2. 인기 급상승 웹툰 10개 가져오기
3. 만화 "남편을 죽여줘요"의 제목, 링크, 평점 가져오기
워크 샵을 시작하기 앞서 Web Scraping 이론과 Web Scraping을 위한 기본 지식에 대해 먼저 살피겠다.
| Web Scraping 이론
- 스크랩 이란? 신문이나 잡지에서 원하는 글이나 사진을 오려 모으는 것
- Web Scraping이란? 컴퓨터 소프트웨어 기술을 활용해 웹 사이트 내에 있는 정보를 추출하는 것
| Web Scraping 을 위한 기본 지식
%%writefile C:\Users\Playdata\HTML_example.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>이것은 HTML 예제</title>
</head>
<body>
<h1>출간된 책 정보</h1>
<p id="book_title">이해가 쏙쏙 되는 파이썬</p>
<p id="author">홍길동</p>
<p id="publisher">위키북스 출판사</p>
<p id="year">2018</p>
</body>
</html>- <!doctype html> : 문서가 html임을 명시하기 위한 DTD(Document Type Definition) 선언
- Tag : < >로 둘러 쌓인 부분으로 <태그>는 시작 태그 </태그>는 끝 태그라고 한다.
- 속성(Attributes) : 시작 태그 안에 부가적인 정보를 제공
- 요소(Elements) : 시작 태그 ~ 끝 태그 그리고 그 안에 포함된 전체 내용을 태그의 요소 요소 내부에는 일반 텍스트 뿐만 아니라 태그를 포함하는 다른 요소도 넣을 수 있다.
ex) <p id="book_title"> 이해가 쏙쏙 되는 파이썬</p>
p는 태그 id는 속성값 ('<p id="book_title">')는 요소라고 할 수 있다.
# WorkShop1
요일별 전체 웹툰 제목 모두 가져오기
필요한 import를 선언 해주고 스크랩핑 할 url과 본인의 User-agent를 header로 선언해준다.
User-agent는 사용자마다 각각 다른 OS와 버전등을 쓰고 있기 때문에 그런 정보를 담아준다고 생각하면 됩니다.
# import 및 별칭 선언
import requests as req
from bs4 import BeautifulSoup as bea# url 및 headers 선언
url = "https://comic.naver.com/webtoon/weekday"
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"}
res = req.get(url, headers)User-Agent는 본인 User-Agent를 넣어줘야 한다. User-Agent를 검색하거나,
개발자 모드에서(F12) -> Network -> Headers에서 볼 수 있다.
참고 ) User-Agent 보는 방법
Option 1)
https://www.whatismybrowser.com/detect/what-is-my-user-agent/
What is my user agent?
Every request your web browser makes includes your User Agent; find out what your browser is sending and what this identifies your system as.
www.whatismybrowser.com
Option 2) 개발자 모드에서(F12) -> Network -> Headers

url 주소가 잘 요청되는지 status_code로 확인합니다.
200대는 정상 400대는 비정상입니다.
# 응답 확인
res.status_code
결과 : 200BeautifulSoup을 이용하여 가져옵니다. (bea로 별칭줌)
prettify()는 예쁘게 보여줍니다.
soup = bea(res.text, 'lxml')
print(soup.prettify())
요일별 전체 웹툰 제목을 모두 가져오기 위하여 먼저 웹툰 제목을 선택합니다.
개발자 모드(F12) -> 마우스 커서(select an element in the page to inspect it) -> 제목(알기 원하는 부분) ->
마우스 오른쪽 -> Copy -> Copy selector
결과 : #content > div.list_area.daily_all > div:nth-child(1) > div > ul > li:nth-child(1) > a

select를 이용하여 가져온다.
soup.select("#content > div.list_area.daily_all > div:nth-child(1) > div > ul > li:nth-child(1) > a")원하는 제목인 "참교육"을 가져온다는 것을 확인 할 수 있다.

원하는 것이 전체 웹툰의 제목이기 때문에 find_all을 써준다.
soup.find_all('a', {"class":"title"})이부분이 항상 어려운 것 같다. 어떻게 태그와 속성을 추출하는지 이해가 잘 되지 않는다.
그래서 혼자 정리를 해보았다(정답X)
soup.find('전체 태그', {"전체 태그의 속성":"원하는 값 속성"})
전체 태그는 a이고, 속성은 class라서 soup.find_all('a', {"class": 까지 작성해주고,
나머지 title은 원하는 제목을 가진 속성이 title이라서 title이라고 작성해서 최종 아래와 같다.
soup.find_all('a', {"class":"title"})
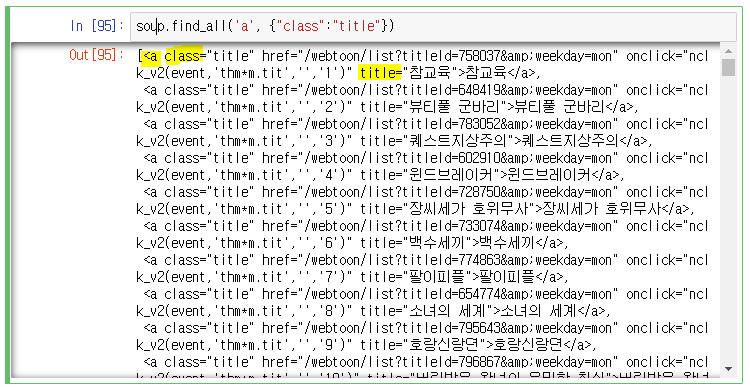
그리고 "제목"을 추출하고 위하여 .get_text()를 사용할 것인데, get_text()는 find_all 혹은 select에 사용할 수 없기 때문에 for문을 사용하여 추출해준다.
또한 .get_text()는 마지막에 와야한다.
titles = soup.find_all('a', {"class":"title"})
for title in titles:
print(title.get_text())
내일은 인기 급상승 웹툰 10개 가져오기를 해보겠습니다. 감사합니다 :)
'💻 개발과 자동화' 카테고리의 다른 글
| [Web Scraping] os 모듈과 chunk로 하나의 이미지 저장하기 (4) | 2022.10.18 |
|---|---|
| [Web Scraping] 네이버웹툰 - 인기 웹툰 및 제목, 링크, 평점 가져오기 (8) | 2022.10.10 |
| [Python] Module - 모듈 import, 내장 모듈 사용 (0) | 2022.10.05 |
| [Python] 데이터 다루기 - split, strip, join, find, count, replace 등 (2) | 2022.10.04 |
| [Python] 파이썬 OOP 완전 기초 | 클래스, 메서드, 상속 정리 (0) | 2022.09.26 |




댓글