. 개요
1.1. 참고
9.1 이하 버전: https://www.cubrid.org/manual/ko/9.1.0/ha.html
9.2 이상 버전: https://www.cubrid.org/manual/ko/9.2.0/ha.html
현재 기준으로 10.1은 국문 릴리즈 버전이 나오지 않아서 9.2 이상 릴리즈 버전을 보고 HA구성을 해도 크게 다를게 없다. 나의 cubrid 버전은 10.1이다. 하지만 9.2 이상의 버전의 사람들인 9.1 이하의 릴리즈 버전을 보고 설치하면 다른게 꽤 있다.
10.1 버전: https://www.cubrid.org/manual/en/10.1/ha.html#quick-start
1.2. Cubrid HA
1.2.1. HA이란?
High Availability(HA)란, 하드웨어, 소프트웨어, 네트워크 등에 장애가 발생해도 지속적인 서비스를 제공하는 기능이다.
CUBRID의 HA 기능은 shared-nothing 구조이며, 액티브 서버(active server)에서 스탠바이 서버(standby server)로 데이터를 동기화하기 위해 다음 두 단계를 수행한다.
1. 트랜잭션 로그 다중화: 액티브 서버에서 생성되는 트랜잭션 로그를 실시간으로 다른 노드에 복제한다.
2. 트랜잭션 로그 반영: 실시간으로 복제된 트랜잭션 로그를 분석하여 스탠바이 서버에 데이터를 반영한다.
CUBRID HA 기능은 시스템과 CUBRID의 상태를 실시간으로 감시하고 장애가 발생하면 자동 failover를 수행하기 위해 heartbeat 메시지를 사용한다.
1.2.2. 노드와 그룹
노드는 CUBRID HA를 구성하는 논리적인 단위로, 노드는 상태에 따라 마스터 노드(master node), 슬레이브 노드(slave node), 레플리카 노드(replica node) 등으로 나눈다.
• 마스터 노드 : 복제의 대상이 되는 노드로, 액티브 서버를 사용한 읽기, 쓰기 등 모든 서비스를 제공한다.
• 슬레이브 노드: 마스터 노드와 동일한 내용을 갖는 노드로, 마스터 노드의 변경이 자동으로 반영된다. 스탠바이 서버를 사용한 읽기 서비스를 제공하며 마스터 노드 장애 시 failover가 일어난다.
• 레플리카 노드 : 마스터 노드와 동일한 내용을 갖는 노드로, 마스터 노드의 변경이 자동으로 반영된다. 스탠바이 서버를 사용한 읽기 서비스를 제공하며 마스터 노드 장애 시 failover가 일어나지 않는다.
•
1.2.3. 서버
서버란 데이터베이스 서버 프로세스를 논리적으로 표현하는 단어로, 상태에 따라 액티브 서버(active server), 스탠바이 서버(standby server)로 나눈다.
• 액티브 서버 : 마스터 노드에 속하는 서버로, active 상태이다. 액티브 서버는 사용자에게 읽기, 쓰기 등 모든 서비스를 제공한다.
• 스탠바이 서버 : 마스터 노드 외의 노드에 속하는 서버로, standby 상태이다. 스탠바이 서버는 사용자에게 읽기 서비스만을 제공한다.
1.2.4. heartbeat
heartbeat 메시지
HA 기능을 제공하기 위한 핵심 구성 요소로, 마스터 노드, 슬레이브 노드, 레플리카 노드가 다른 노드의 상태를 감시하기 위해 주고 받는 메시지이다. heartbeat 메시지는 cubrid_ha.conf 의 ha_port_id 파라미터에 설정된 UDP 포트로 주고 받는다.
1.2.5. Failover와 failback
failover와 failback
failover란, 마스터 노드에 장애가 발생하여 서비스를 제공할 수 없는 상태가 되면 우선순위가 가장 높은 슬레이브 노드가 자동으로 마스터 노드가 되는 것이다.
1.2.6. Cubrid 브로커
참고: https://d2.naver.com/helloworld/1197
DBMS 서버와 클라이언트 모듈이 동작하는 구조는 그대로 두고 자바, PHP 등의 요청을 처리할 수 있는 중간 레이어를 두어서 애플리케이션이 사용하는 드라이버는 상대적으로 단순한 작업만 처리하고, 중간 레이어와 DBMS 서버가 요청을 처리하는 형태를 생각해 볼 수 있다. 이때 드라이버와 DBMS 서버의 중간 레이어 역할을 수행하는 것이 바로 CUBRID 브로커이다.
2. Cubrid HA 구성 시작
2.1. 구성도

CUBRID HA는 Windows를 지원하지 않는다.
2.2. 초기세팅
2.2.1. IP주소
네트워크 대역대 추가
File -> Host Network Manager



ip 대역대를 추가하지 않고 기존에 사용하던 ip 주소를 사용해도 무관하다.
- Adapter1: NAT
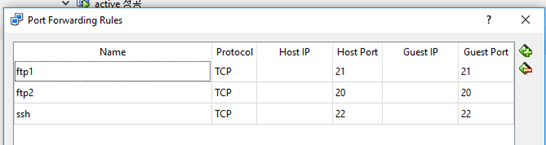
Putty 접속 하고 싶으면 => Adapter 1 -> NAT -> Adavanced -> Port Forwarding
22번 포트 추가
20번과 21버는 ftp를 사용하기 위해 추가함.
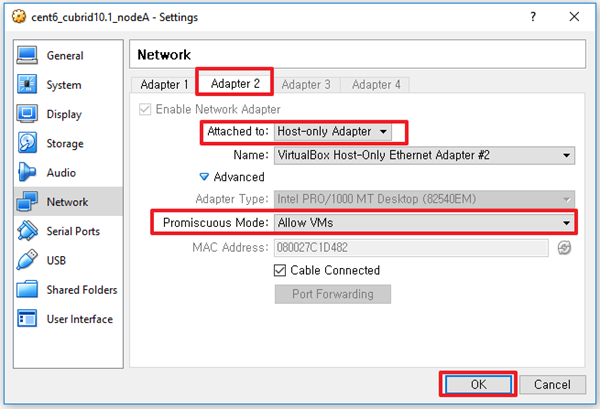
- Adapter2: Host-only Adapter
[root@nodeA ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth1 --eth1없으면 생성
|
DEVICE=eth1 ONBOOT=yes IPADDR=169.254.173.252 NETMASK=255.255.255.0 BOOTPROTO=static NM_CONTROLLED=no |

[root@nodeA ~]# service network restart --network 적용
2.2.2. HOST명 변경
2.2.2.1. /etc/sysconfig/network
- 영구적인 방법
vi /etc/sysconfig/network
|
NETWORK=yes HOSTNAME=nodeA |
- 일시적인 방법
hostname nodeA
두가지 방법중에 영구적인 방법으로 바꿔놓도록 하자.
2.2.2.2. /etc/hosts
nodeA와 nodeB 통신을 위해 /etc/hosts에 추가

변경 후 reboot로 재시작
변경되었는지 확인

2.2.3. 방화벽 OPEN
7, 1523, 59901 포트를 열어두어야 한다. 아니면 master와 slave가 소통이 되지 않아 HA가 정상동작 되지 않는다.
vi /etc/sysconfig/iptables
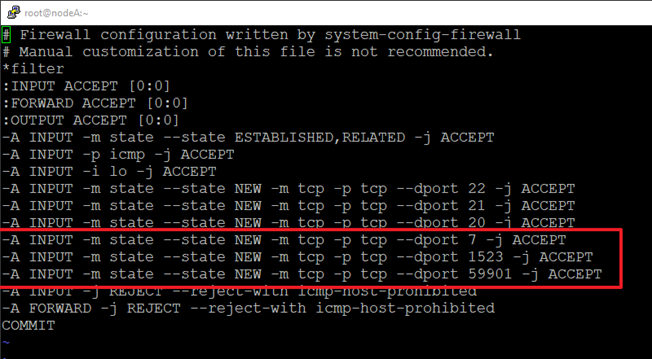
service iptables restart
여기까지 Cubrid HA에 관해 알아보고 초기세팅을 했다.
이제 Cubrid HA 구성을 데이터베이스 생성 및 서버 설정을 해보도록 한다.
2.3 데이터베이스 생성 및 서버 설정
2.3.1 데이터베이스 생성
CUBRID HA에 포함할 데이터베이스를 모든 CUBRID HA 노드에서 동일하게 생성
ð 모든 cubrid ha 노드에서 동일하게 생성해야하지만 nodeA만 생성하고 복제를 하기로 하자.
[cub_user@nodeA rpm]$ cd $CUBRID_DATABASES
[cub_user@nodeA databases]$ mkdir testdb
[cub_user@nodeA databases]$ cd testdb
[cub_user@nodeA testdb]$ mkdir log
[cub_user@nodeA testdb]$ cubrid createdb -L ./log testdb en_US.iso88591
잘 만들어졌는지 확인

csql> ;exit --sql 나오는 명령어

2.3.2 cubrid.conf
$CUBRID/conf/cubrid.conf 의 ha_mode 를 모든 HA 노드에 동일하게 설정한다. 특히, 로깅 관련 파라미터인 log_max_archives 와 force_remove_log_archives, HA 관련 파라미터인 ha_mode 의 설정에 주의한다.
cubird.conf 파일 건드리기 전에 백업
[cub_user@nodeA conf]$ cp cubrid.conf cubrid.conf.bak
[cub_user@nodeA rpm]$ vi $CUBRID/conf/cubrid.conf
|
# HA 구성 시 추가 (Logging parameters) log_max_archives=100 force_remove_log_archives=no
# HA 구성 시 추가 (HA 모드) ha_mode=on |

2.3.3. cubrid_ha.conf
수정전 백업
[cub_user@nodeA conf]$ cp cubrid_ha.conf cubrid_ha.conf.bak
<수정전>

<수정후>
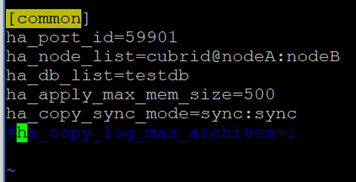
2.3.4 databases.txt
[cub_user@nodeA conf]$ vi $CUBRID_DATABASES/databases.txt
<변경전>
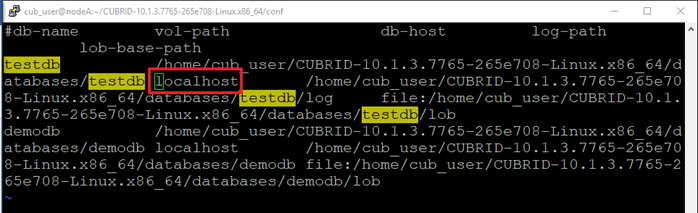
<변경후>

다음에는 slave 서버인 nodeB설정과 Cubrid HA 동작 여부, 시작, failover 테스트, 에러 해결에 대해서 다뤄보도록 하겠다.
https://seul96.tistory.com/173
Cubrid HA - 2 (slave 서버 설정)
큐브리드 HA란, cubrid HA 초기세팅, cubrid master 서버 설정이 궁금하면: https://seul96.tistory.com/172?category=843617 Cubrid HA - 1 (HA란, 초기세팅, master 서버 설정) 1. 개요 1.1. 참고 9.1 이하 버전..
seul96.tistory.com
'💻 개발과 자동화' 카테고리의 다른 글
| MVC Architecture (0) | 2020.02.24 |
|---|---|
| Cubrid HA - 2 (slave server setting) (0) | 2020.02.19 |
| CentOS7 putty Connect Error (2) | 2020.02.11 |
| Servlet JDBC (1) | 2020.01.20 |
| BLOB data create & Encryption/Decryption (0) | 2020.01.17 |




댓글