오라클 SQL과 PL/SQL을 다루는 기술 참조
* Check
데이터를 체크해 특정 조건에 맞는 데이터만 입력 받고 그렇지 않으면 오류를 뱉어 낸다.
Constraint 체크명 check(체크조건)
| create table ex2_9( Num1 number Constraints check1 check(num1 between 1 and 9), Gender varchar2(10) Constraints check2 check (gender in (‘male’, ‘femaile’)) ); |
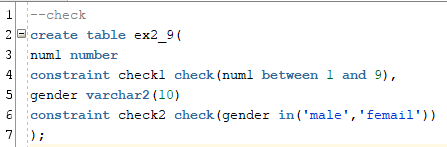
제약 조건에 위배되는 데이터를 넣어보면
insert into ex2_9 values(10, 'man');
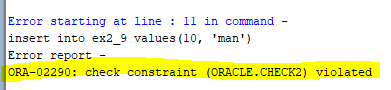
알맞은 데이터 넣기
insert into ex2_9 values(9, 'male');
결과: 1 row inserted.
* 테이블 복사
| Create table [스키마.]테이블명 as Select 컬럼1, 컬럼2, …. From 복사할 테이블명; |
Create table … as의 앞 글자를 따서 ctas(씨타스)라고 부르기도 하는데 정식 명칭은 아니다. 이 구문을 사용하면 테이블 구조와 데이터가 모두 신규 테이블로 복사된다.
create table ex2_9_1 as select * from ex2_9;
* 뷰
뷰는 하나 이상의 테이블이나 다른 뷰의 데이터를 볼 수 있게 하는 데이터베이스 객체다. 실제 데이터는 뷰를 구성하는 테이블에 담겨 있지만 마치 테이블처럼 사용할 수 있다. 또한 테이블 뿐만 아니라 다른 뷰를 참조해 새로운 뷰를 만들어 사용할 수 있다. 데이터를 본다는 의미가 있으므로 뷰의 정의는 데이터를 조회하는 select문으로 구성된다.
뷰는 테이블이나 또 다른 뷰를 참조하는 객체이므로 뷰 생성 스크립트는 다른 테이블이나 뷰를 select 하는 구문으로 구성된다. 사원 테이블에는 부서번호만 존재하고 부서명은 없다. 따라서 해당 사원이 속한 부서명을 보려면 다음과 같이 부서 테이블을 참조해야 한다.
Create or replace view [스키마.]뷰명 as select 문장;
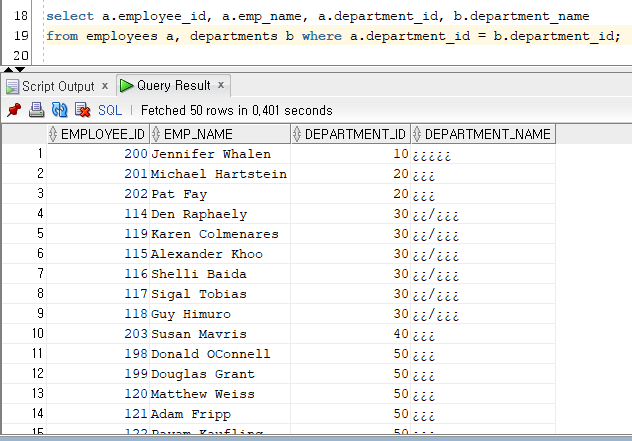
그런데 위의 정보를 여러 사람이 자주 사용해야 한다면 너무 비효율적이다. 이럴 때는 사원번호, 사원명, 부서번호, 부서명을 볼 수 있는 뷰를 만들어 놓고 이 뷰를 참조하면 매우 편리하다.
| create or replace view emp_dept_v1 as select a.employee_id, a.emp_name, a.department_id, b.department_name from employees a, departments b where a.department_id = b.department_id; |
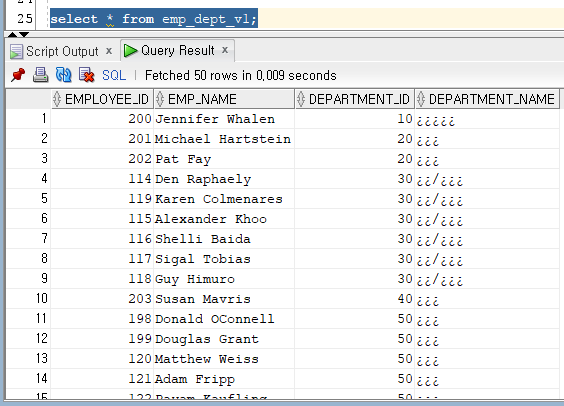
여러 개의 테이블에서 필요한 정보를 뽑아 사용할 때가 많은데 이때 선택할 수 있는 최선책이 바로 뷰다. 또한 뷰는 데이터 보안 측면에서 유리하다. 즉 뷰를 보면 컬럼과 데이터만 공개되므로(뷰 생성시 컬럼명도 변경 가능), 원천 테이블을 감출 수 있다. 특히 뷰가 참조하는 테이블 소유자가 아닌 다른 사용자가 해당 뷰를 사용해야 할 경우, 그 사용자는 원천 테이블에 대한 정보를 전혀 볼 수 없다.
- 뷰 삭제
Drop view [스키마.]뷰명;
뷰 삭제는 간단하고 뷰는 다른 테이블을 참조하고 있으므로 뷰를 삭제하더라도 실제 데이터는 삭제 되지 않는다. 또한 뷰를 수정하는 구문은 생성 구문과 동일하다. 또한 뷰를 통해 원천 테이블에 있는 데이터를 조작하는 것이 가다. 이런 뷰를 updatetable 뷰라고 한다.
* 인덱스
인덱스는 테이블에 있는 데이터를 빨리 찾기 위한 용도의 db 객체다.
1) 인덱스 구성 컬럼 개수에 따른 분류: 단일 인덱스와 결합 인덱스
2) 유일성 여부에 따른 분류: unique 인덱스, non-unique 인덱스
3) 인덱스 내부 구조에 따른 분류: b-tree 인덱스, 비트맵 인덱스, 함수 기반 인덱스
1) 과 2)는 인덱스 형태와 속성에 따른 분류이며, 3)은 구조와 내부 알고리즘에 따른 분류로 보면 된다. 이 외에도 해시 클러스터 인덱스, 리버스 키 인덱스, 비트맵 조인 인덱스, 도메인 인덱스, 파티션 인덱스가 있다. 가장 일반적인 인덱스는 b-tree 인덱스이다.
Create[unique] index [스키마명.] 인덱스명 on [스키마명.]테이블명(칼럼1, 칼럼2, …);
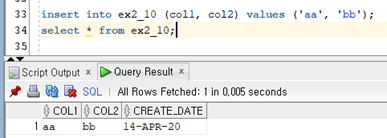
컬럼 속성 중 하나로 default라는 것이 있다. 이는 컬럼의 디폴트 값을 명시하는데 사용된다. Date 타입에 default 디폴트 값 형식으로 기술하면 자동으로 디폴트 값이 들어 간다.
인덱스가 생성되면 user_indexes 시스템 뷰에서 내역을 확인해 볼 수 있다.
select * from user_indexes where TABLE_NAME='EX2_10';
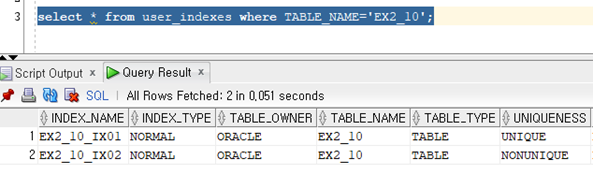
주의해야 할 점으로는 테이블 name의 대소문자를 지켜줘야 한다.
소문자 ex2_10으로 입력하면 결과가 나오지 않음.
create unique index ex2_10_ix01 on ex2_10 (col1);
unique 인덱스가 만들어 졌는데, 이는 col1값에 중복 값을 허용하지 않는다는 뜻이다. 인덱스가 생성되면 user_indexes 시스템 뷰에서 내역을 확인해 볼 수 있다.
별도로 unique 인덱스를 생성하지 않아도 unique 제약조건을 만들면 오라클은 자동으로 unique 인덱스를 생성해준다. 더불어 기본키를 생성해도 오라클은 자동으로 unique 인덱스를 생성해 준다. 이때 생성되는 인덱스명은 unqiue나 기본키 객체명과 동일하게 생성된다.
결합인덱스
또한, 한 개 이상의 컬럼으로 인덱스를 만들 수 있는데, 이를 결합 인덱스라고 한다.
인덱스는 테이블에 있는 데이터를 빨리 찾기 위한, 즉 조회 성능을 높이려는 목적에서 만들어 졌고 인덱스 자체에 키와 매핑 주소 값을 별도로 저장한다. 따라서 테이블에 데이터를 입력하거나 삭제, 수정할 때 인덱스에 저장된 정보도 이에 따라 생성, 수정이 이루어진다.
인덱스를 생성할 떄 고려해야 할 사항을 정리하면 다음과 같다.
1) 일반적으로 테이블 전체 로우 수의 15%이하의 데이터를 조회할 때 인덱스를 생성한다.
2) 테이블 건수가 적다면(코드성 테이블) 굳이 인덱스를 만들 필요가 없다.
3) 데이터의 유일성 정도가 좋거나 범위가 넓은 값을 가진 컬럼을 인덱스로 만드는 것이 좋다
4) Null이 많이 포함된 컬럼은 인덱스 컬럼으로 만들기 적당치 않다.
5) 결합 인덱스를 만들 때는, 컬럼의 순서가 중요하다. (보통 자주 사용되는 컬럼을 순서상 앞에 두는 것이 좋다)
6) 테이블에 만들 수 있는 인덱스 수의 제한은 없으나, 너무 많이 만들면 오히려 성능 부하가 발생한다.
인덱스 삭제
Drop index [스키마명.]인덱스명;
* 시노님
시노님은 ‘동의어’란 뜻이다. 시노님에는 public과 private 시노님이 있다. Public은 ‘공동’이란 의미가 있듯이 public 시노님은 db의 모든 사용자가 접근할 수 있다. 이에 반해 private 시노님은 특정 사용자에게만 참조되는 시노님이다.
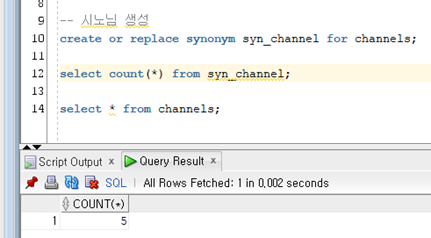
시노님 생성
| Create or replace [public] synonym [스키마명.]시노님명 For[스키마명.]객체명; |
Public을 생략하면 private 시노님이 만들어 진다. 참고로 public 시노님은 dba 권한이 있는 사용자만 생성 및 삭제가 가능하다. For절 이하의 객체에는 테이블, 뷰, 프로시저, 함수, 패키지 시퀀스 등이 올 수 있다.
User 변경
alter user hr identified by hr account unlock;
select 권한 주기
grant select on syn_channel to hr;
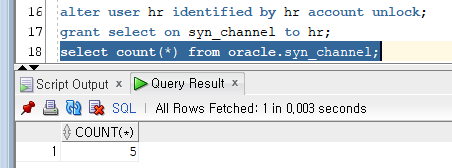
Public 시노님은 소유자명을 붙이지 않아도 참조가 가능한데, 그 이유는 해당 시노님의 소유자가 시노님을 만든 oracle이 아닌 public이 되기 때문이다. 생성된 시노님 정보는 private은 user_synonyms, public까지 보려면 all_synonyms를 참조하면 된다.
시노님을 사용하는 이유를 정리해 보면 다음과 같다.
1) Db의 투명성을 제공하기 위해서 사용. 다른 사용자의 객체를 참조할 때 많이 사용
…
시노님 삭제
Drop [public] synonym [스키마명.]시노님명;
Private 시노님을 제거할 때 drop synonym이나 drop any synonym 권한이 있어야 하며, public 시노님을 제거할 때는 drop public synonym 권한이 있어야 한다. Public 시노님을 제거할 때는 public이라는 키워드를 명시해야 한다.
* 시퀀스
시퀀스는 자동 순번을 반환하는 db 객체다.
| Create sequence [스키마명.]시퀀스명 Increment by 증감숫자 Start with 시작숫자 Nominvalue | minvalue 최솟값 Nomaxvalue | maxvalue 최댓값 Nocycle | cycle Nochache | cache; |
Nocycle: default 값, 최대나 최소값에 도달하면 생성 중지
Cycle: 증가는 최댓값에 도달하면 다시 최솟값부터 시작, 감소는 최소값에 도달하면 다시 최댓값에서 시작
Nochache: 디폴트로 메모리에 시퀀스 값을 미리 할당해 놓지 않으면 디폴트 값은 20
Cache: 메모리에 시퀀스 값을 미리 할당해 놓음.
| create table ex2_8( col1 varchar2(10) primary key, col2 varchar2(10) ); |
insert into ex2_8(col1) values (my_seq1.nextval);
시퀀스명.nextval을 사용하면 해당 시퀀스에서 다음 순번 값을 자동으로 가져온다. 또한 시퀀스명.currval을 사용하면 해당 시퀀스의 현재 값을 알 수 있다.
주의할 사항은 nextval을 사용하면 값이 계속 증가된다. 즉 insert문이 아닌 select문에서 사용하더라도 값이 증가된다.
시퀀스 삭제
Drop sequence[스키마명.]시퀀스명;
* 파티션 테이블
파티션 테이블 (근데 이거 안되는데 왜 안되는지 모르겠음)
파티션이라 함은 테이블에 있는 특정 컬럼값을 기준으로 데이터를 분할해 저장해 놓는 것이다.
예를 들어, 샘플 스키마에 매출정보가 있는 sales 테이블은 총 91만여 건의 데이터가 담겨 있다. 이 테이블에서 특정 데이터를 찾으려면 91만 건을 모두 뒤져봐야 한다. 이때 테이블에 있는 판매일자(sales_date)와 판매월(sales_month) 컬럼을 이용해 조회할 때의 성능을 높여 보자. 판매월별로 데이터를 분할해 놓고 데이터 조회 시 특정을 월을 조건으로 걸면 전체 데이터를 뒤져보지 않아도 된다.
만약 2000년 11월에 판매된 특정 상품 판매데이터를 검색한다고 하면,
1) 파티션이 없는 경우: 91만여 건을 모두 뒤져 조건에 맞는 데이터를 걸러낸다.
2) 파티션이 있는 경우: 2000년 11월 데이터(19,000여건)만 뒤져 조건에 맞는 데이터를 걸러낸다.
이처럼 대용량 테이블은 파티션을 만들어 놓는 것이 훨씬 유리하다. 파티션 테이블 생성도 create table을 사용한다. Sales 테이블 생성 구문을 살펴보자.
'💻 개발과 자동화' 카테고리의 다른 글
| [JEUS] linux jeus7 use + jsp 화면 띄우기 (2) | 2020.05.07 |
|---|---|
| [JEUS] linux jeus7 install (0) | 2020.04.29 |
| Database package (0) | 2020.03.16 |
| merge, insert, alter, delete (0) | 2020.03.12 |
| MVC Architecture (0) | 2020.02.24 |




댓글