[AWS-EC2 Hadoop|Hive|Spark] Hadoop 3.2 설정파일 설정
| System Structure

여섯째날인 오늘은 Hadoop 설정파일을 설정하겠습니다.
앞 전 포스트에서 Hadoop 구조에 대해서 설명을 했지만 다시 짧게 설명을 하자면,
AWS 비용 문제로 Namenode는 datanode1역할도 합니다.
SecondaryNameNode는 datanode2 역할도 합니다. 또한 부하 문제로 Resource Manager역할을 SecondaryNameNode가 합니다.
그리고 datanode3과 client로 구성되어있습니다.
목차
1. Hadoop 설정파일 설정
1.1 core-site.xml
1.2 hdfs-site.xml
1.3 yarn-site.xml
1.4 mapred-site.xml
1.5 workers
2.AWS - EC2 보안 그룹 수정
3. (참고) AWS-EC2 파일질라 접속
내용
1. Hadoop 설정파일 설정
Hadoop을 사용하기 위해서는 $HADOOP_HOME/etc/hadoop 밑에 있는 5개의 파일을 수정해야 합니다.
core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml, workers
[root@ip-172-31-40-48 ~]# su - hadoop
Last login: Sun Dec 4 05:50:04 UTC 2022 on pts/0
[hadoop@ip-172-31-40-48 ~]$ cd $HADOOP_HOME/etc/hadoop/
[hadoop@ip-172-31-40-48 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@ip-172-31-40-48 hadoop]$ ls -al

1.1 etc/hadoop/core-site.xml
[hadoop@Namenode hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@Namenode hadoop]$ vi core-site.xml
| Parameter | Value | Notes |
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | Size of read/write buffer used in SequenceFiles. |
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020/</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
1.2 etc/hadoop/hdfs-site.xml
[hadoop@Namenode hadoop]$ vi hdfs-site.xml
| Parameter | Value | Notes |
| dfs.namenode.name.dir | NameNode가 네임스페이스와 트랜잭션 로그를 지속적으로 저장하는 로컬 파일 시스템의 경로입니다. | 이것이 쉼표로 구분된 디렉토리 목록인 경우 중복성을 위해 이름 테이블이 모든 디렉토리에 복제됩니다. |
| dfs.datanode.data.dir | 블록을 저장해야 하는 DataNode 의 로컬 파일 시스템에서 쉼표로 구분된 경로 목록입니다 . | 이것이 쉼표로 구분된 디렉토리 목록인 경우 데이터는 일반적으로 다른 장치에 있는 명명된 모든 디렉토리에 저장됩니다. |
또한 dfs.namenode/secondary/datanode.http-address value값을 통해서는 각각의 namenode, secondarynode, datanode를 웹상으로 접속하여 실행 상태를 확인 할 수 있습니다.
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/data/name1,file:///home/hadoop/data/name2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>namenode:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>secondnode:50090</value>
</property>
<property>
<name>dfs.datanode.http-address</name>
<value>0.0.0.0:50010</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/hadoop/data/namesecondary</value>
</property>
</configuration>
1.3 etc/hadoop/yarn-site.xml
[hadoop@Namenode hadoop]$ vi yarn-site.xml
| Parameter | Value | Notes |
| yarn.resourcemanager.hostname | ResourceManager 호스트. | host 모든 yarn.resourcemanager*address 리소스 를 설정하는 대신 설정할 수 있는 단일 호스트 이름입니다 . ResourceManager 구성 요소에 대한 기본 포트가 생성됩니다. |
| yarn.nodemanager.local-dirs | 중간 데이터가 기록되는 로컬 파일 시스템의 쉼표로 구분된 경로 목록입니다. | 다중 경로는 디스크 I/O를 분산시키는 데 도움이 됩니다. |
| yarn.nodemanager.aux-services | mapreduce_shuffle | Map Reduce 애플리케이션에 대해 설정해야 하는 셔플 서비스입니다. |
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>secondnode</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/data/nm</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
</configuration>
1.4 etc/hadoop/mapred-site.xml
mapreduce.jobhistory.address와 mapreduce.jobhistory.webapp.address는 MapReuce JobHistory 서버 구성입니다.
[hadoop@Namenode hadoop]$ vi mapred-site.xml
| Parameter | Value | Notes |
| mapreduce.framework.name | yarn | Hadoop YARN으로 설정된 실행 프레임워크. |
| mapreduce.jobhistory.address | MapReduce JobHistory 서버 호스트:포트 | 기본 포트는 10020입니다. |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory 서버 웹 UI 호스트:포트 | 기본 포트는 19888입니다. |
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>namenode:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>namenode:19888</value>
</property>
</configuration>
1.5 etc/hadoop/workers
[hadoop@Namenode hadoop]$ vi workers
NameNode를 위해 일할 작업자의 HostName 혹은 IP 주소를 한 줄에 하나씩 나열합니다.
저는 datanode를 2개로 했지만 3개를 원하시면 그 아래 datanode3를 추가해도 됩니다.
datanode1
datanode2
datanode3
2.AWS - EC2 보안 그룹 수정
다음날에는 인스턴스를 복사해 서버를 추가적으로 만들것입니다. 서버들끼리 원할한 통신을 위하여 보안그룹을 수저하겠습니다.
네트워크 및 보안 -> 보안 그룹 -> 나의 보안그룹 검색 및 선택 -> 인바운드 규칙 -> 인바운드 규칙 편집


aws는 default 값으로 SSH는 열려있습니다.
인스턴스 처음 생성 때, 제 IP 대역대 끼리 모든 TCP를 통신하게 설정했습니다.
여기서 보안그룹끼리 자유로운 통신을 하게 추가 할것입니다.
규칙 추가방법은,
규칙 추가 -> 자신의 보안그룹 선택 -> 규칙저장

최종 보안 규칙은 아래와 같습니다.
1. SSH
- 유형 : SSH
- 소스: 모든 IP
2. 모든 TCP
- 유형 : 모든 TCP
- 소스 : 나의 IP 대역대
3. 모든 보안그룹 끼리
- 유형 : 모든 TCP
- 소스 : 나의 보안 그룹

3. (참고) AWS - EC2 파일질라 접속
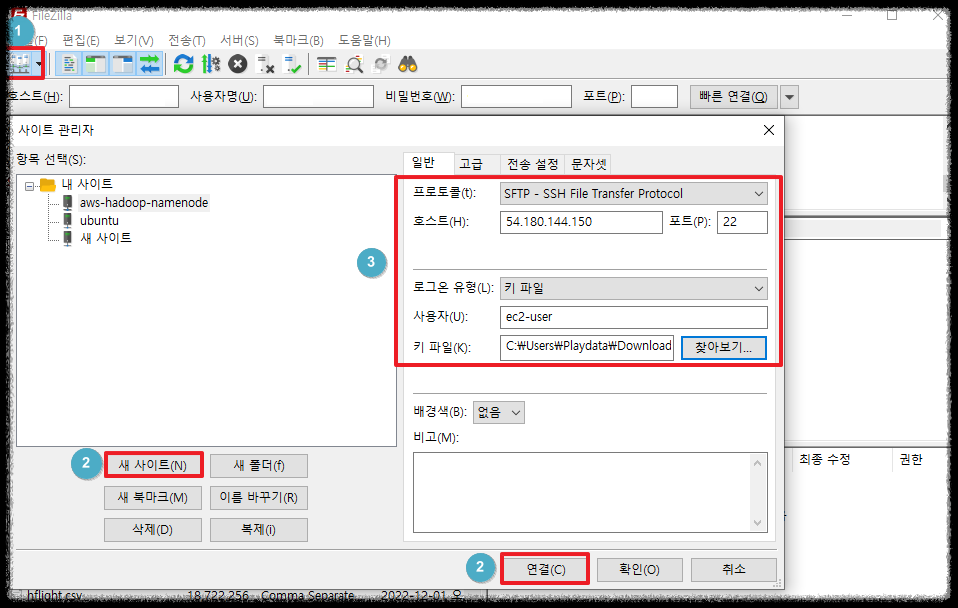
서버 모양 -> 새 사이트 -> 사이트 정보 입력 -> 연결
(이름을 수정하고 싶으시면 이름 바꾸기를 누르고 확인을 선택합니다)
- 프로토콜 : SFTP
- 호스트: PUBLIC DNS 혹은 IP
- 포트 : 22 혹은 안적어도 됨.
- 로그온 유형 : 키 파일
- 사용자 : ec2-user
-> ubuntu 운영체제 사용자는 ubuntu 입력
- 키 파일 : aws 만든 .ppk 선택
올리고 싶은 파일을 선택하고 마우스 오른쪽 -> 업로드를 선택하면
/home/ec2-user에 업로드 된것을 확인 할 수 있습니다.

반대로 리눅스에서 윈도우로 보내고 싶으면 리모트 사이트에서 보내고 싶은 파일 선택후 다운로드를 선택하면 됩니다.

[hadoop@ip-172-31-40-48 hadoop]$ su -.
Password: root패스워드 입력
[root@ip-172-31-40-48 ~]# cd /home/ec2-user/
[root@ip-172-31-40-48 ec2-user]# ls
[root@ip-172-31-40-48 ec2-user]# mv * /home/hadoop/hadoop/etc/hadoop/
mv: overwrite '/home/hadoop/hadoop/etc/hadoop/core-site.xml'? y
mv: overwrite '/home/hadoop/hadoop/etc/hadoop/hdfs-site.xml'? y
mv: overwrite '/home/hadoop/hadoop/etc/hadoop/mapred-site.xml'? y
mv: overwrite '/home/hadoop/hadoop/etc/hadoop/workers'? y
mv: overwrite '/home/hadoop/hadoop/etc/hadoop/yarn-site.xml'? y
[root@ip-172-31-40-48 ec2-user]# chown -R hadoop:hadoop /home/hadoop/hadoop/etc/hadoop
[root@ip-172-31-40-48 ec2-user]# ls -al /home/hadoop/hadoop/etc/hadoop/
