[AWS-EC2 Hadoop|Hive|Spark] Hdfs 파일 포맷, Hdfs/Yarm 시작 종료
| SystemStructure

목차
1. Hdfs 파일 포맷
2. HDFS, YARM 시작 종료
2.1 Hdfs, Yarm 시작
2.2 Hdfs, Yarm 구동 확인
2.2.1 jps로 확인
2.2.2 Web에서 확인
2.23 Hadoop 테스트
2.3 Hdfs, Yarm 종료
내용
1. Hdfs 파일 포맷
[hadoop@Namenode hadoop]$ hdfs namenode -format

2. HDFS, YARM 시작 종료
2.1 Hdfs, Yarm 시작
[hadoop@Namenode hadoop]$ start-dfs.sh

[hadoop@secondnode data]$ start-yarn.sh
저는 Resource Manager가 SecondaryNameNode에 위치했기 때문에 second 서버에서 start-yarm.sh 명령어를 했습니다.
NameNode에 Resource Manager가 있으면 NameNode서버에서 start-yarm.sh를 하시기 바랍니다 :)

[hadoop@Namenode hadoop]$ mapred --daemon start historyserver

2.2 Hdfs, Yarm 구동 확인
2.2.1 jps로 확인
2.2.1.1 NameNode, DataNode1, Job History
[hadoop@Namenode data]$ jps
5137 DataNode
5013 NameNode
5687 Jps
5451 NodeManager
5629 JobHistoryServer
2.2.1.2 Secdondary NameNode, DataNode2, Resource Manager
[hadoop@secondnode data]$ jps
5344 Jps
4737 SecondaryNameNode
4614 DataNode
4858 ResourceManager
4972 NodeManager
2.2.1.3 DataNode3
[hadoop@datanode3 ~]$ jps
2915 DataNode
3044 NodeManager
3193 Jps
2.2.1.4 Client
[hadoop@client ~]$ jps
2142 Jps

2.2.2 Web에서 확인
2.2.2.1 NameNode
http://NameNode설치서버_publicDNSorIP:50070
저는 NameNode서버에 NameNode를 설치했기 때문에 아래와 같이 접속했습니다.
AWS는 재시작시 마다 Public DNS와 IP가 바뀌기 때문에 확인해야 합니다.
현재 기준
- NameNode, History Server의 DNS : ec2-15-165-159-119.ap-northeast-2.compute.amazonaws.com
- SecondaryNode그리고Resource Manager DNS : ec2-3-36-128-89.ap-northeast-2.compute.amazonaws.com
http://ec2-15-165-159-119.ap-northeast-2.compute.amazonaws.com:50070/

접속이 안되는 분들은 포트 번호를 확인해보세요.
1. port 번호 확인 -> 50070
cat /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
<name>dfs.namenode.http-address</name>
<value>namenode:50070</value>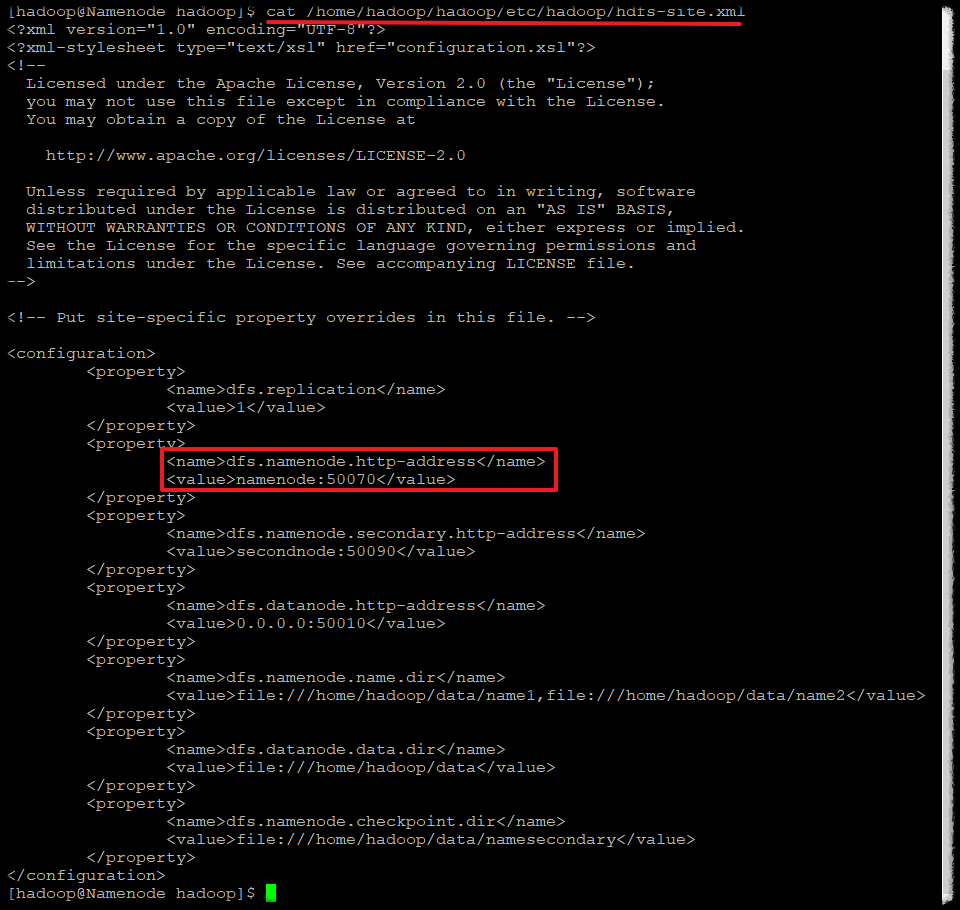
2. Port가 실행중인지 확인
netstat -tulpn | grep LISTEN
tcp 0 0 172.31.40.48:50070 0.0.0.0:* LISTEN 5013/java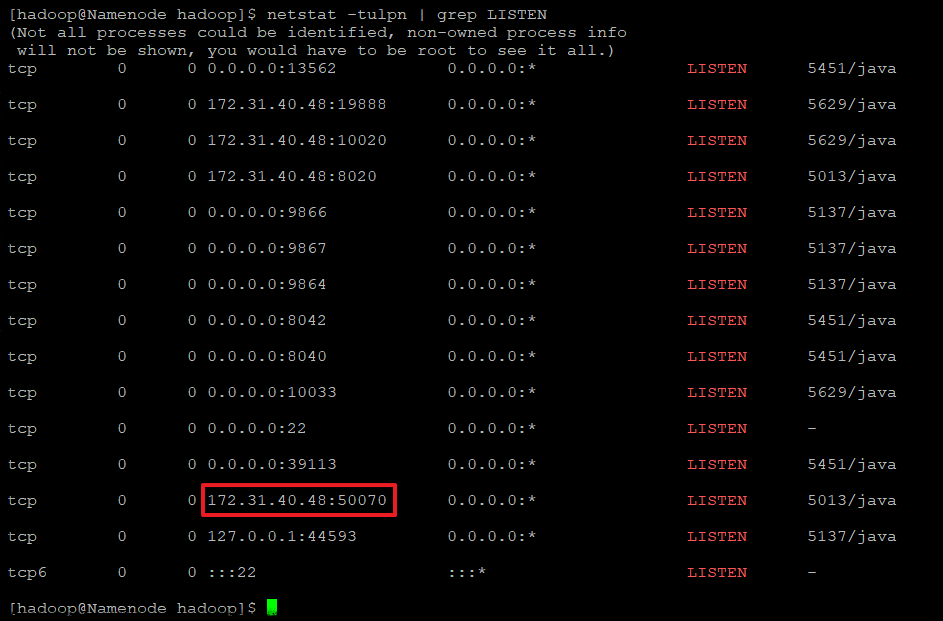
2.2.2.2 Secondary NameNode
http://NameNode설치서버_publicDNSorIP:50090
http://ec2-3-36-128-89.ap-northeast-2.compute.amazonaws.com:50090/

접속이 안되는 분들은 아래를 확인해보세요.
1. port 번호 확인 -> 50090
cat /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
<name>dfs.namenode.secondary.http-address</name>
<value>secondnode:50090</value>
2. Port가 실행중인지 확인
netstat -tulpn | grep LISTEN
tcp 0 0 172.31.38.6:50090 0.0.0.0:* LISTEN 4737/java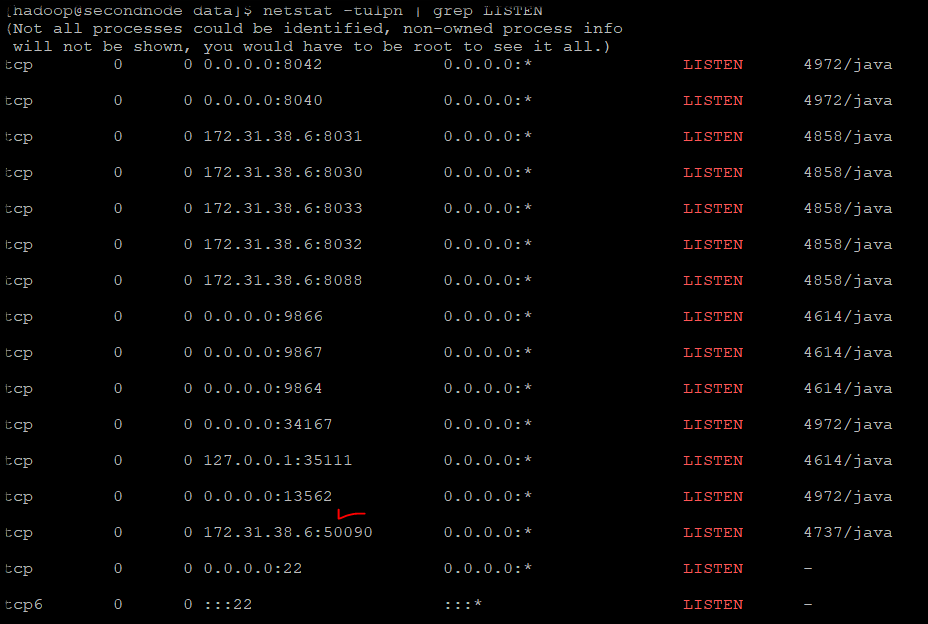
2.2.2.3 Reousr Manager
http://Resource Manager 설치서버_publicDNSorIP:8088
-> 저는 Second 서버가 Resource Manager입니다.
http://ec2-3-36-128-89.ap-northeast-2.compute.amazonaws.com:8088/

접속이 안되는 분들은 아래를 확인해보세요.
1. port 번호 확인 -> 8088
참조 : https://hadoop.apache.org/docs/r3.2.3/hadoop-project-dist/hadoop-common/ClusterSetup.html

2. Port가 실행중인지 확인
netstat -tulpn | grep LISTEN
tcp 0 0 172.31.38.6:8088 0.0.0.0:* LISTEN 4858/java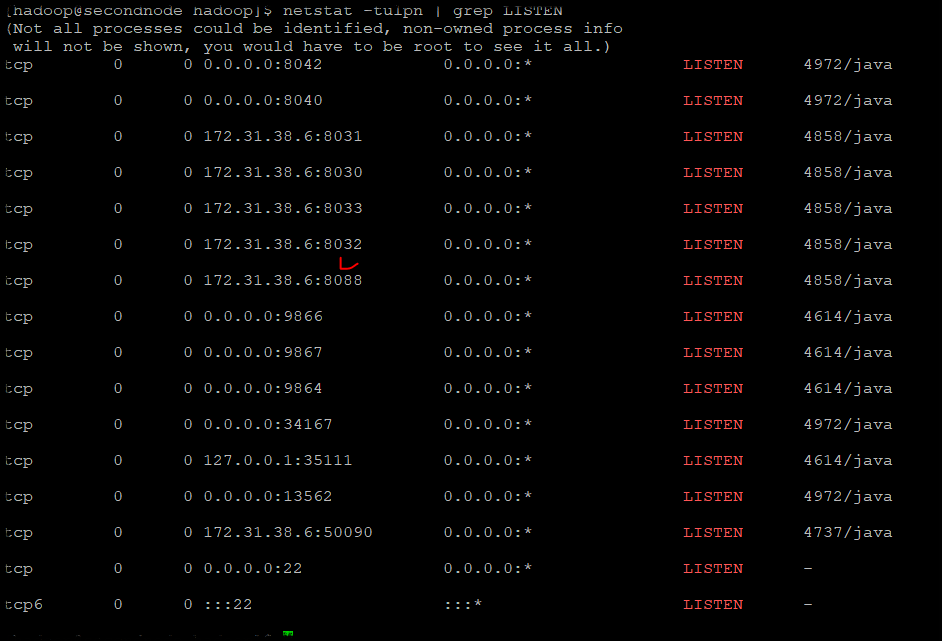
2.2.2.4 JobHistory Server
http://JobHistory Server 설치서버_publicDNSorIP:19888
-> 저는 namenode 서버에 같이 jobhistory server를 설치했습니다.

접속이 안되는 분들은 아래를 확인해보세요.
1. port 번호 확인 -> 19888
참조 : https://hadoop.apache.org/docs/r3.2.3/hadoop-project-dist/hadoop-common/ClusterSetup.html

2. Port가 실행중인지 확인
netstat -tulpn | grep LISTEN
tcp 0 0 172.31.40.48:19888 0.0.0.0:* LISTEN 5629/java
2.2.3 Hadoop 테스트
[hadoop@Namenode hadoop]$ hdfs dfs -mkdir -p /hadoop-dir/test
[hadoop@Namenode hadoop]$ echo "HelloWorld" > HelloWorld.txt
[hadoop@Namenode hadoop]$ hdfs dfs -copyFromLocal HelloWorld.txt /hadoop-dir/test

이제 잘 올라갔는지 확인을 해보겠습니다.
http://ec2-15-165-159-119.ap-northeast-2.compute.amazonaws.com:50070/
Utilities -> Browse the file system -> 만든 폴더 Name선택 -> 만든 폴더 확인


2.3 Hdfs, Yarm 종료
namenode, resource manager 그리고 job history 서버에 맞춰 종료 명령어를 실행해주세요.
[hadoop@secondnode hadoop]$ stop-dfs.sh
Stopping namenodes on [namenode]
Stopping datanodes
Stopping secondary namenodes [secondnode]
[hadoop@Namenode hadoop]$ mapred --daemon stop historyserver

[hadoop@Namenode hadoop]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
