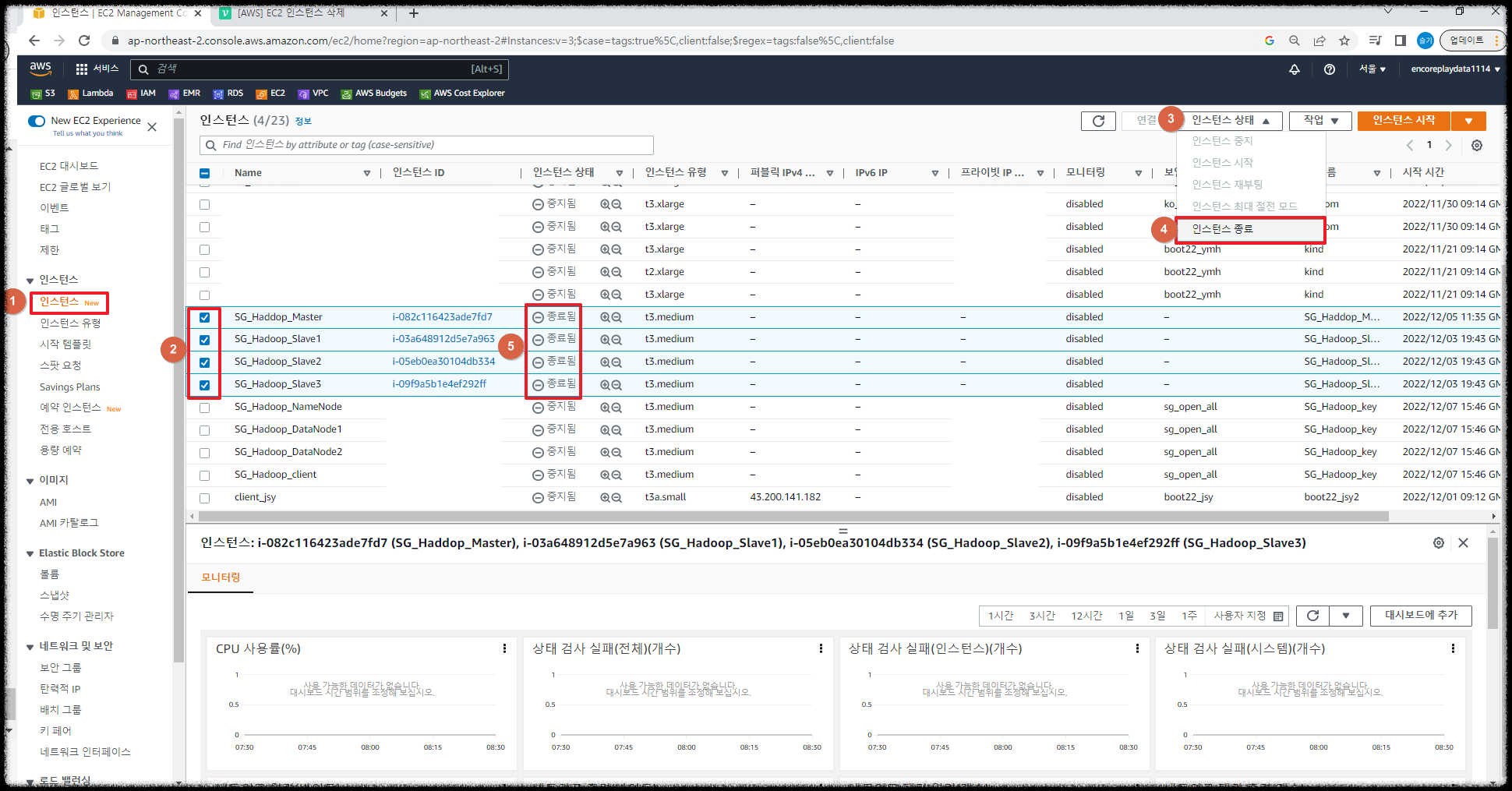
[AWS-EC2 Hadoop|Hive|Spark] 인스턴스 복사(AMI 생성) + 이미지/인스턴스 삭제
| System Structure
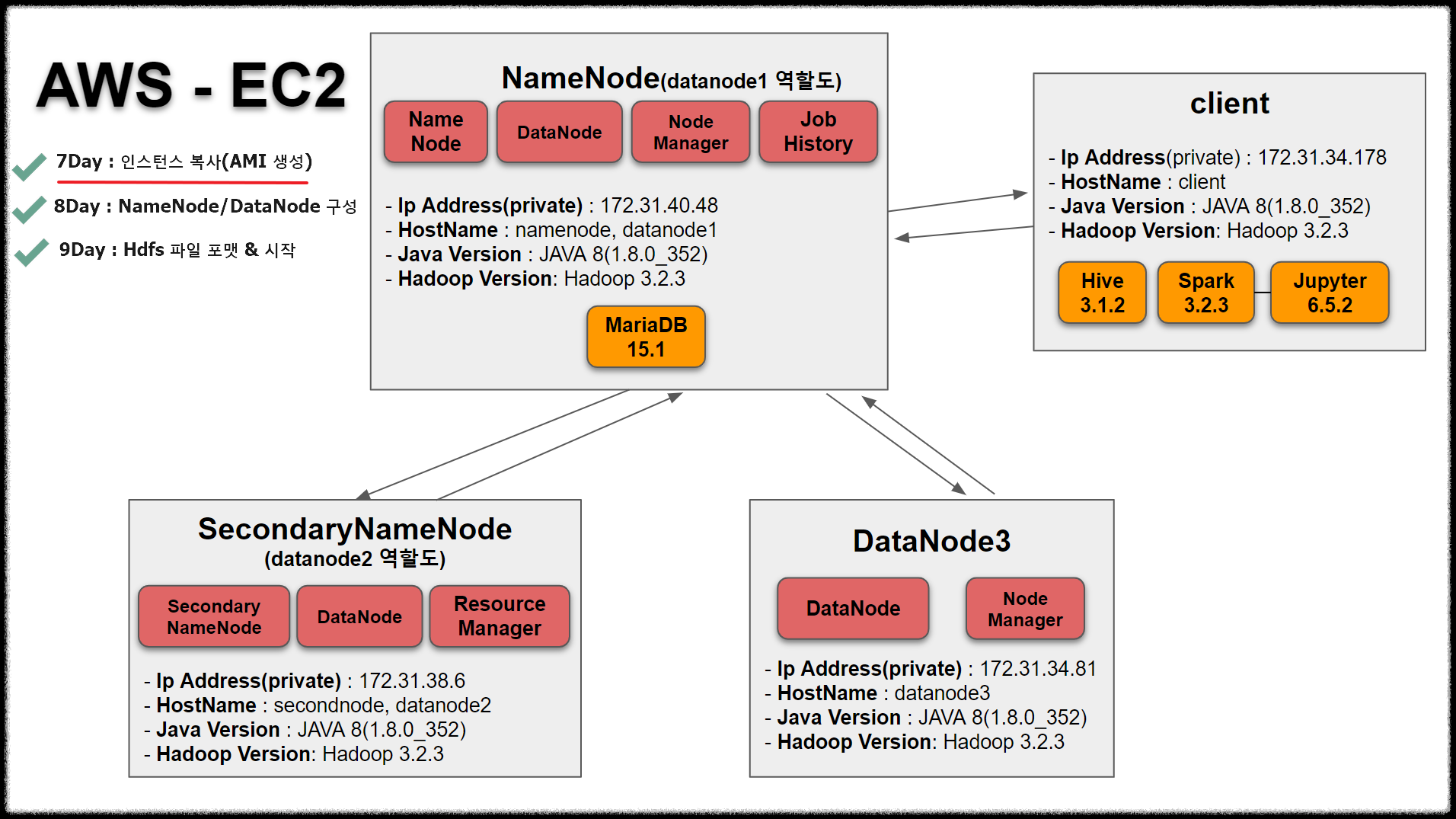
일곱째날인 오늘은 인스턴스를 복사해서 총 서버 4대를 만들겠습니다.
목차
1. 이미지 생성 및 설정
2. 인스턴스 시작 및 설정
3. (참고) 이미지 삭제
4. (참고)인스턴스 삭제
내용
지금까지는 공통적인 Hadoop을 구성했다고 생각하시면 됩니다.
시스템 구성도를 보면 서버는 총 4대입니다.
namenode(=datadnode1), secondarynode(datanode2), datanode3 그리고 client 서버입니다.
AMI 이미지로 만들어 인스턴스를 3개 복사해서 총 4개의 서버를 만들겠습니다.
AWS에서는 Amazon Machine Image라는 AMI 기능을 제공해 쉽게 인스턴스를 복사할 수 있습니다.
(유료이지만 이미 생성되어있는 이미지를 구입할 수도 있습니다)
VirtualBox에 스냅샷과 비슷하다고 생각하시면 될듯 합니다.
1. 이미지 생성 및 설정
1.1 이미지 생성
EC2 -> 인스턴스 -> 복사하고 싶은 인스턴스 체크 -> 작업 -> 이미지 및 템플릿 -> 이미지 생성

1.2 이미지 설정
* 이미지 이름 : SG_Hadoop
(SG는 내 이름 슬기의 약자)
* 인스턴스 볼륨 : 20GB

2. 인스턴스 시작 및 설정
2.1 인스턴스 시작
이미지(AMI) -> 시작하고 싶은 이미지 체크 -> AMI로 인스턴스 시작

2.2 인스턴스 설정
* 이름 및 태그 : SG_Hadoop_DataNode
* 애플리케이션 및 os 이미지:
기존 인스턴스처럼 Redhat을 사용할것이기 때문에 아무것도 선택하지 않음
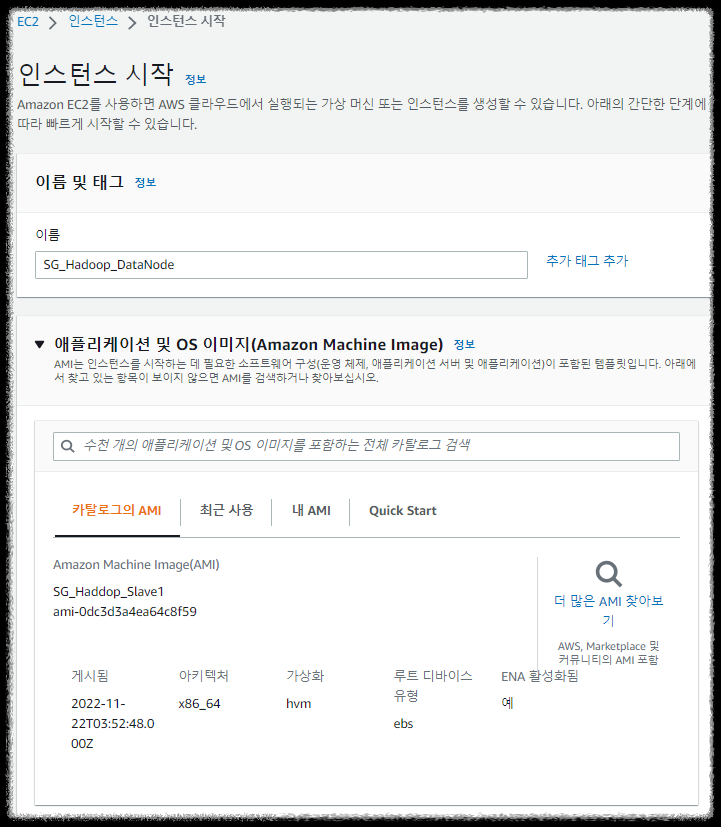
* 인스턴스 유형 : t3.medium
* 키 페어(로그인)
- 이름 : SG_Hadoop_key
-> Namenode key를 동일하게 사용하겠습니다.
* 네트워크 설정
- 기존 보안 그룹 선택
기존에 이미 생성해놓은 내부 IP끼리는 모든 통신이 가능하도록하는 보안그룹을 동일하게 사용하겠습니다.

* 스토리지 구성
-> 기존 인스턴스처럼 20gb

datanode로 2대, Client 서버 1대가 추가적으로 더 필요하기 때문에 인스턴스 개수를 3개를 했습니다.
그러면 총 3개의 서버가 생성됩니다.
마지막으로 인스턴스 시작을 클릭합니다.

모든 인스턴스 보기를 선택하면 몇 초(혹은 몇분 후) 설정한 이름(SG_Hadoop_DataNode)으로 인스턴스 3대가 생성됩니다.
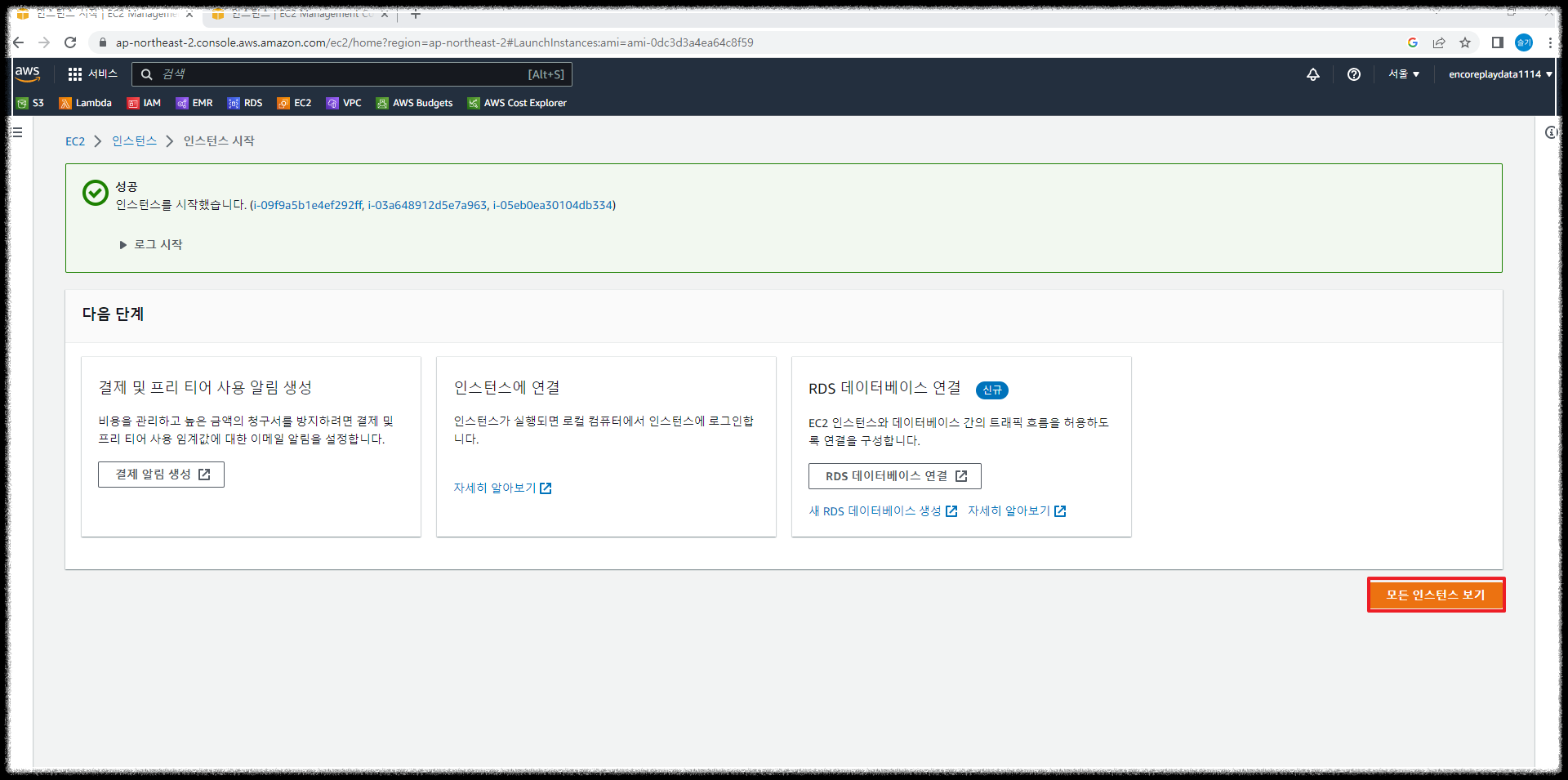
이름을 각각 변경합니다.
저는 Hadoop_datanode1, 2 client로 했습니다.
(datanode1, 2, 3으로 해도 상관없습니다)
마지막으로 저장을 클릭합니다.

3. (참고) 이미지(AMI) 삭제
잘못 만들었거나 혹은 이제 사용하지 않은 이미지를 삭제하고 싶은 경우는 아래와 같이 이미지를 삭제 할 수 있습니다.
EC2 -> 이미지(AMI) -> 삭제하고 싶은 AMI 체크 -> 작업 -> AMI 등록 취소
https://ap-northeast-2.console.aws.amazon.com/ec2

연결된 스냅샷 삭제 선택하고 "스냅샷 화면에서 삭제할 수 있습니다" 링크는 클릭만 해주세요.
그리고 AMI 등록 취소를 선택하고 "스냅샷 화면에서 삭제할 수 있습니다" 링크로 돌아갑니다.
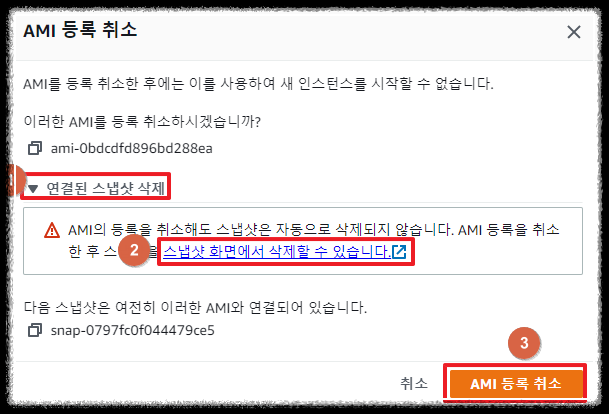
삭제 하고 싶은 스냅샷 ID 체크 -> 작업 -> 스냅샷 삭제 -> 삭제


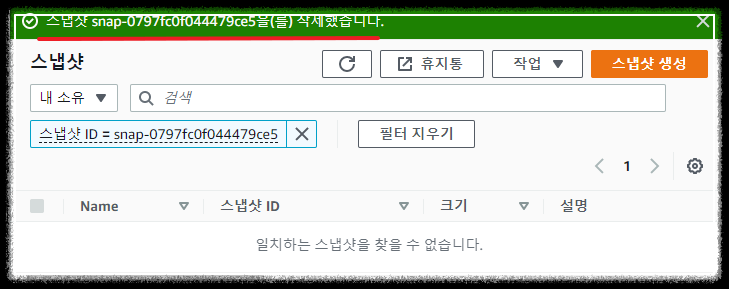
"스냅샷을 삭제했습니다"라는 문구와 함께 스냅샷이 삭제된것을 확인할 수 있습니다.
4. (참고) 인스턴스 삭제
인스턴스 -> 삭제하고 싶은 인스턴스 선택 -> 인스턴스 상태 -> 인스턴스 종료
몇시간 후에 인스턴스 목록에서 삭제된것을 확인할 수 있다.